W tym wpisie chcę zademonstrować prostą sztuczkę, która nie jest jeszcze powszechnie znana, a jest już dostępna od jakiegoś czasu w debugerze GDB. Chodzi o funkcję reverse-exection, która weszła w wersji 7 GDB. Reverse-execution to oczywiście wykonywanie wstecz instrukcji programu.
Zademonstrujmy to może na prostym programie napisanym w C:
#include <stdlib.h>
int main()
{
int x;
x = rand();
x = rand();
x = rand();
return 0;
}
Skompilujmy go z flagami debugowymi:
gcc -g test.c -o test
Jak widać program nie robi nic mądrego, losowo generuje trzy liczby.
Uruchommy ten program w GDB:
gdb ./test
Włączmy wykonywanie programu komendą start:
(gdb) start
...
Temporary breakpoint 1, main () at test.c:7
7 x = rand();
Program powinien zatrzymać się na pierwszej linijce i i tak się dzieje. Aby móc skorzystać z reverse-execution należy włączyć nagrywanie wykonywania kodu:
(gdb) record
Teraz możemy przechodzić po jednej linijce i obserwować jak się zmieniała wartość zmiennej x:
(gdb) next
8 x = rand();
(gdb) print x
$1 = 1804289383
Ale powiedzmy, że zapomnieliśmy sprawdzić, jaką wartość miał wcześniej x, aby to zrobić wykorzystamy instrukcję reverse-next:
(gdb) reverse-next
No more reverse-execution history.
main () at test.c:7
7 x = rand();
(gdb) print x
$2 = 0
Po przednio x miał wartość 0.
Komenda step też ma swój odpowiednik w postaci reverse-step. Nagrywanie nie musi być włączone od razu po uruchomieniu GDB, może ono zostać włączone gdy dotrzemy do problematycznego dla nas fragmentu kodu.
Powyższy przykład jest może nieco głupkowaty, ale w prosty sposób obrazuje jak używać tego mechanizmu. Może się to okazać przydatne podczas analizy kodu, gdzie wykonywane są jakieś złożone operacje i w trakcie jego wykonywania coś przestaje nam się zgadzać, wtedy nie musimy uruchamiać debugera ponownie tylko wystarczy, że wykonamy odpowiednią ilość kroków wstecz.
W tym artykule chcę zwrócić na nagminny błąd pojawiający się w artykułach o prognozowaniu cen akcji za pomocą sieci neuronowych. Błąd ten można spotkać m. in. w tym artykule w serwisie medium i w tym artykule w serwisie towardsdatascience.
Wiadomym jest, że sieci neuronowe preferują wyskalowane dane wejściowe, jednak skalowanie szeregów czasowych(a szeregi cen akcji są szeregami czasowymi) wcale nie jest takie oczywiste jakby się mogło wydawać i nie można tego dokonać za pomocą MinMaxScalera z pythonowego pakietu Scikit Learn co jest nagminne w artykułach w sieci.
To co jest właściwie problemem?
Aby zobrazować ten problem weźmy może na tapet cenę Assecopolu(ticker ACP) i go przeskalujmy za pomocą MinMaxScalera:
Dla uproszczenia kodu pominąłem wczytywanie danych.
Po takim przeskalowaniu otrzymujemy taki oto wykres:
Wykres ceny ACP przeskalowanej za pomocą MinMaxScalera
Porównajmy to z rzeczywistym wykresem ceny:
Wykres ceny ACP
Na pierwszy rzut oka można stwierdzić: “no i gitara, mieliśmy ceny w zakresie od ok. 5 PLN za akcję do ok. 95 PLN, a my przeskalowaliśmy sobie je do zakresu od 0 do 1 czyli tak jak lubią sieci neuronowe”.
Problemem jest to, że skalowaliśmy ceny przeszłe za pomocą cen z przyszłości. Chodzi o to, że cena zamknięcia np. z 10 grudnia 1999 była skalowana za pomocą ceny z 3 marca 2002 co jest błędem w przypadku analizy szeregów czasowych ponieważ 10 grudnia 1999 nie znaliśmy ceny nawet z 11 grudnia więc nie mogliśmy tych cen wykorzystać do skalowania dostępnych danych. Ten błąd nazywany jest zjawiskiem lookahead.
Zjawisko lookahead
Najprościej mówiąc zjawisko lookahead polega na użyciu danych do analizy, które nie były znane w danym momencie przez co na predykcję przyszłych wartości szeregu mają wpływ przyszłe wartości szeregu co nie powinno mieć miejsca. Właśnie po to analizujemy szeregi czasowe żeby poznać ich przyszłe wartości.
Co można z tym zrobić?
Aby rozwiązać ten problem musimy po prostu użyć wartości przeszłych do skalowania szeregu czasowego. Można do tego celu użyć np. kroczącej średniej i kroczącego odchylenia standardowego. Przykładowa implementacja takiego podejścia może wyglądać następująco:
W powyższym przykładzie od aktualnej ceny odejmujemy średnią kroczącą z 10 okresów, otrzymana wartość jest następnie dzielona przez kroczące odchylenie standardowe z takiej samej ilości okresów. Po takiej operacji otrzymujemy taki wykres:
Poprawnie przeskalowany wykres ceny ACP
Nie wygląda to zbyt ładnie, sprawdźmy jak to wygląda dla ostatnich stu sesji:
Poprawnie przeskalowany wykres ceny ACP, 100 ostatnich sesji
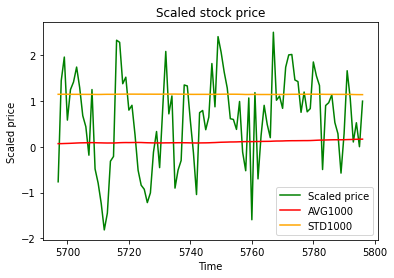
Teraz wykres przeskalowanej ceny wcale nie przypomina oryginalnego wykresu ceny. Warto zwrócić uwagę, że otrzymany szereg czasowy możemy uznać za szereg stacjonarny tj. w długim okresie jego średnia wynosi ok. 0, a odchylenie standardowe ok. 1(czyli są stałe) co może być istotne dla niektórych analityków:
Odchylenie standardowe kroczące i średnia kroczące dla przeskalowanej ceny ACP
Tak przeskalowany szereg możemy wykorzystać jako dane wejściowe do sieci neuronowej.
Jakiś czas temu stwierdziłem, że na komputerach z 16 lub więcej gigabajtami RAMu bez sensu jest robić na dysku przestrzeń wymiany popularnie zwaną swapem. Uznałem to za marnotrawstwo miejsca na dysku. Okazało się jednak, że byłem w błędzie, ld potrafi jednak przy linkowaniu większych projektów zeżreć dużo więcej niż 16GB RAMu. Wtedy w mojej głowie pojawiło się pytanie co z tym zrobić, przecież nie będę przeinstalowywać systemu żeby zrobić sobie partycje na swapa specjalnie dla jednego zadania.
Okazuje się, że rozwiązanie tego problemu jest bardzo proste. Swap nie musi być partycją, może być po prostu plikiem.
Powyższa komenda utworzy plik o rozmiarze 16GB. Następnie musimy sformatować jako przestrzeń wymiany:
mkswap swapfile.bin
Do swapa dostęp powinien mieć tylko użytkownik root więc wypada zmienić uprawnienia:
chmod 600 swapfile.bin
Na koniec musimy uruchomić swapa:
swapon swapfile.bin
Po ostatniej komendzie w programach typu top czy w monitorze systemu swap powinien być widoczny.
Aby powyższa zmiana była na stałe należy zmodyfikować plik /etc/fstab poprzez dodanie:
/ścieżka/do/swapfile.bin swap swap defaults 0 0
Jak się okazuje nawet przy RAMie o przyzwoitym rozmiarze swap bywa potrzebny i to nie trzeba robić nic nadzwyczajnego, wystarczy kompilacja nieco większego projektu.
To byłoby na tyle co chciałem przedstawić w tym kursie. Masz już sporo wiedzy nt. budowania Linuksa, wiesz z jakich komponentów się składa system, jak to wszystko przebudować i jak to wszystko połączyć aby cały system działał. Zatem idź w świat buduj Linuksy i szerz wiedzę o nich.
Dalsze kroki
Aby lepiej przyswoić wiedzę przedstawioną w kursie najlepiej było przygotować dystrybucje Linuksa idealnie przystosowaną do twoich potrzeb. Przykładowo możesz chcieć przygotować dystrybucję dla systemu monitoringu. W takim przypadku potrzeba by dodać do systemu obsługę sieci oraz całe oprogramowanie obsługujące kamery i pewnie jeszcze jakieś inne elementy, które nie przychodzą mi w tym momencie do głowy.
Twoim kolejnym krokiem może być również głębsze zapoznanie się z kernelem i pisaniem modułów do niego. Zamierzam na ten temat przygotować kurs.
Inną ścieżką dalszej edukacji może być zapoznanie się z pracą w samym Linuksie jako systemie i dowiedzenie się jak implementować różne komponenty systemu takie jak np. demony.
Polecane lektury
Tematyka tego kursu nie jest zbyt popularna w polskojęzycznych źródłach, zmuszony jestem zatem polecić jedynie anglojęzyczne pozycje:
Mastering embedded Linux programming, Chris Simmonds- książka ta rozszerza tematykę tego kursu więc jeśli chcesz poszerzyć zdobytą już wiedzę możesz sięgnąć po tę książkę
Exploring BeagleBone, Derek Molloy- książka poświęcona płytce BeagleBone Black, jest tam wiele informacji od sposobu podłączania elementów do płytki po implementację obsługi tychże elementów w Linuksie
Exploring Raspberry Pi, Derek Molloy- co prawda nie czytałem tej książki jednak ekstrapoluje tutaj moje pozytywne wrażenie nt. książki Exploring BeagleBone na inną pozycję od tego samego autora, spis treści wygląda interesująco. Zatem jeśli chcesz się dobrze zapoznać z RPi możesz rzucić okiem na tę książkę
Jądro Linuksa, Robert Love- pozycja dla osób chcących się dowiedzieć więcej nt. Działania kernela Linux
Linux. Programowanie systemowe, Robert Love- książka przedstawiająca jak pisać oprogramowanie dla Linuksa, dokładny przegląd biblioteki standardowej czyli zarządzanie plikami, procesami, pisanie demonów itp.
Pierwszym procesem uruchomionym po starcie kernela jest proces init, posiada on identyfikator(PID, process ID) 1 i jest rodzicem dla wszystkich procesów uruchomionych później w systemie. Jeśli init nie zostanie znaleziony lub nie może być uruchomiony kernel rzuci błędem „Kernel panic” co było widoczne w lekcji dotyczącej kernela. Podczas startowania systemu program init, który ma zostać uruchomiony może zostać wskazany w parametrach kernela za pomocą opcji „init=/ścieżka/do/programu/init”. System może być uruchomiony dopóki działa proces o PIDzie 1, wydanie komendy:
kill 1
Ta komenda powinna być równoznaczna z resetem lub wyłączeniem urządzenia. Przetestuj to na swojej platformie.
Obecnie programy init są dostarczane przez init systemy. Init systemy oprócz tego, że odgrywają rolę pierwszego procesu w systemie umożliwiają również zarządzanie serwisami czy jak kto woli demonami systemowymi.
Do najpopularniejszych init systemów należą:
BusyBox- jest to mały system o stosunkowo małych możliwościach, często jest wykorzystywany na systemach wbudowanych
System V init- do niedawna to ten init system królował w zastosowaniach desktopowych czy serwerowych teraz został wyparty przez nowszy systemd. BusyBox jest w zasadzie ograniczoną wersją System V przystosowaną do małych urządzeń
systemd- jest to obecnie najpopularniejszy init system w zastosowaniach desktopowych(jest jakiś dobry polski zamiennik na to słowo?) i serwerowych. Jest to bardzo zaawansowany init system, oprócz tego, że umożliwia zarządzanie demonami umożliwia również synchronizację pomiędzy startowanymi demonami podczas uruchamiania systemu.
Sam osobiście spotkałem się jeszcze z init systemem runit w systemie OpenWRT nie wiem jednak jak wygląda sprawa z jego popularnością. Buildroot oprócz użycia trzech wcześniej wymienionych init systemów umożliwia również użycie OpenRC, jest to init system używany m.in. przez dystrybucje Gentoo.
Jeśli chcesz zmienić init system w Buildrootcie to w menuconfigu musisz przejść zakładki „System configuration”, tam będzie dostępna opcja „Init system”.
Domyślnym wyborem w Buildrootcie jest BusyBox, ze względu na jego prostotę zapoznamy się z nim.
BusyBox
BusyBox podczas uruchamiania używa pliku konfiguracyjnego /etc/inittab. Plik ten definiuje, które programy mają zostać uruchomione i kiedy. Na każdy program przypada jedna linijka pliku w formacie:
terminal::zdarzenie:komenda
Terminal to konsola wyjściowa danego programu, nie trzeba tego parametru podawać, domyślnie będzie to terminal wskazany w parametrach startowych systemu. Można również podać wartość „null” gdy uruchamiamy demona i proces taki z definicji nie jest przypisany do żadnego terminala.
BusyBox umożliwia wykonanie komendy w reakcji na następujące zdarzenia:
sysinit- wykonanie komendy podczas uruchomienia
respawn- uruchamia program kiedy ten kończy działanie. Jest to używane razem z demonami
askfirst- robi to samo co respawn jednak prosi najpierw o potwierdzenie uruchomienia poprzez wciśnięcie entera, jest to używane podczas uruchamiania shella bez potrzeby podawania użytkownika lub hasła
once- wywołuje komendę raz
wait- wywołuje komendę i czeka aż ta zakończy działanie
restart- uruchamia komendę gdy proces init otrzyma sygnał SIGHUP, który informuje BusyBox, że ma przeładować plik inittab
ctrlaltdel- uruchamia komendę gdy proces init otrzyma sygnał SIGINT
shutdown- uruchamia komendę gdy proces init kończy działanie czyli najprawdopodbniej podczas wyłączania urządzenia
Możesz trochę poeksperymentować z plikiem /etc/inittab i pododawać do niego np. takie wpisy:
::sysinit:/bin/hello
::respawn:/bin/hello # uwaga, to zaśmieci całą konsolę
::ctrlaltdel:/bin/echo "Łożesz ty! SIGINTem? We mnie" # przetestuj komendą
# kill -2 1
::shutdown:/bin/echo "Si ja lejter!"
Plik /etc/inittab możesz edytować zarówno na uruchomionej platformie jak i podłączyć swoją kartę pamięci(podmontować obraz dysku w przypadku QEMU) i edytować plik na swoim komputerze.
Skrypty BusyBoksa
W katalogu /etc/init.d znajdują się skrypty, które umożliwiają interakcje z serwisami lub uruchomienie/wyłączenie niektórych komponentów jak np. interfejsy sieciowe. Zgodnie z konwencją taki skrypt powinien przyjmować parametry start, stop i opcjonalnie restart.
Zgodnie z inną konwencją skrypty te swoją nazwę zaczynają od litery S po czym następują dwie cyfry, które określają, który w kolejności dany skrypt ma zostać uruchomiony.
W pliku /etc/inittab możesz zobaczyć, że BusyBox uruchamia skrypt /etc/init.d/rcS, który to wykonuje wszystkie skrypty z parametrem start w odpowiedniej kolejności.
Podczas wyłączania BusyBox wywołuje skrypt /etc/init.d/rcK, który to wywołuje wszystkie skrypty w odwrotnej kolejności do kolejności startowania z parametrem stop.
Dla celów instruktażowych możesz utworzyć przykładowy skrypt o nazwie S50Greetings o następującej zawartości:
Umieść ten plik w katalogu /etc/init.d. Teraz podczas uruchamiania oraz wyłączania systemu zobaczysz odpowiednią wiadomość. Dodatkowo sam możesz wywołać ten skrypt:
Temat modułów został poruszony w lekcji o kernelu, w tej lekcji chciałbym przedstawić sposoby użycia modułów. Lekcja ta ma raczej zasygnalizować Wam ten aspekt ponieważ sądzę, że póki co wasze systemy będą dosyć niewielkie i nie będzie problemem wkompilowywanie wszystkiego do kernela. Podkreślę też na wstępnie, że nie będziemy się tutaj zajmować implementacją żadnego modułu.
Dla przypomnienia. Czym jest moduł? Moduł to komponent, który może zostać załadowany do kernela jak i odładowany(nie wiem czy to najlepsze słowo w tym przypadku) z niego. Skompilowany moduł ma rozszerzeni .ko co jest skrótem od kernel object. Moduły mogą mieć zależności między sobą co może niekiedy utrudniać pracę z nimi.
Mogło się również nasunąć pytanie: „ej, ale mówiłeś, że ten kernel to monotlityczny jest czy coś takiego? W sensie, że to jedna całość jest, to skąd moduły?”. Zgadza się tak mówiłem i podtrzymuję to zdanie. Moduł po załadowaniu staje się częścią kernela. Jaki to ma wpływ na system? Taki jak wspomniano w lekcji o kernelu, jeśli w tym module będzie jakiś błąd to może nam się cały system zawiesić.
Trzeba też mieć na uwadze, że moduły są budowane dla konkretnej wersji kernel. W ogólności możemy zmusić system aby załadował moduł, który był zbudowany dla innej wersji kernela niż używana wersja, ale nie jest to zalecana operacja.
Konfiguracja kernela
W tej lekcji zaczniemy trochę nietypowo bo nie zaczniemy od omówienia tematyki, a od konfiguracji Linuksa. Tak będzie prościej.
Do prezentacji pracy z modułami wykorzystamy trochę zmodyfikowany przykład z poprzedniej lekcji. Przejdź do swoich źródeł kernela i otwórz menuconfig. Opcje, które ostatnio ustawiałeś jako wkompilowane w kernel ustaw teraz jako moduły. Dla przypomnienia były to opcje:
CONFIG_IIO
CONFIG_I2C_MUX
CONFIG_INV_MPU6050_I2C
Jeśli używasz RPi4 to pozostałe opcje, które zmieniałeś czyli:
CONFIG_I2C_CHARDEV
CONFIG_I2C_BCM2835
CONFIG_I2C_BRCMSTB
pozostaw dalej jako wkompilowane w kernel dla uproszczenia.
Gdy już zmienisz ustawienia Linuksa przebuduj go, a następnie wgraj obraz kernela i device-tree do odpowiedniego miejsca na karcie pamięci. Nie przekładaj jeszcze karty do płytki.
Instalacja modułów
Podczas budowania kernela powstaje wiele plików. Do tej pory nas interesowały jedynie dwa- obraz kernela oraz device-tree. Tym razem interesują nas również zbudowane moduły. Ich już trochę jest i raczej nikomu nie chciałoby się kopiować każdego z nich oddzielnie. Zestaw Makefile’i kernelowych dostarcza rozwiązanie tego problemu, wystarczy, że wykonasz następującą komendę:
# BBB
sudo make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- \
INSTALL_MOD_PATH=/media/user/rootfs modules_install
# RPi4
sudo make ARCH=arm64 CROSS_COMPILE=aarch-64linux-gnu- \
INSTALL_MOD_PATH=/media/user/rootfs modules_install
Powyższa komenda instaluje zbudowane moduły pod ścieżką wskazaną przez INSTALL_MOD_PATH w katalogu lib/module/wersja_linuksa. Pamiętaj aby zawsze podawać tę ścieżkę inaczej moduły zostaną zainstalowane na twoim komputerze.
I to wszystko co musimy zainstalować na karcie, żeby mieć pewność, że wszystko się poprawnie zapisało wykonaj komendy:
sync
sudo umount /media/user/*
Teraz możesz przełożyć kartę do swojej płytki i ją uruchomić.
Zaznaczę jeszcze, że gdy używamy buildsystemu takiego jak Buildroot i będziemy budowali za jego pomocą kernel to moduły zostaną załadowane automatycznie.
Dodatkowo warto też zwrócić uwagę, że w systemie mogą się znajdować moduły dla różnych wersji Linuksa.
Ładowanie modułów
Zacznijmy może od tego co się zmieniło w systemie. Przejdź do katalogu w którym znajduje się reprezentacja twojego urządzenia:
# BBB
cd /sys/bus/i2c/device/2-0068
# RPi4
cd /sys/bus/i2c/device/1-0068
Wykonaj komendę ls i czego nie widzisz? Tak brakuje nam katalogu iio:device0, w którym są dostępne wszystkie dane pochodzące od akcelerometra. Ale mamy przecież sterownik do MPU6050 na karcie pamięci więc ogarniemy tak żeby był ten katalog.
Przejdź do katalogu w którym znajduje się moduł do obsługi MPU6050:
cd /lib/modules/wersja_linuksa/kernel/drivers/iio/imu/inv_mpu6050/
Mamy tam dwa moduły, my docelowo chcemy załadować inv-mpu6050-i2c.ko. To ten moduł umożliwia nam obsługę MPU6050 za pomocą magistrali I2C. Spróbujmy go zatem załadować w najprostszy sposób za pomocą programu insmod:
insmod inv-mpu6050-i2c.ko
No i coś nie poszło, pojawiło się kilka błędów:
[ 371.873163] inv_mpu6050_i2c: Unknown symbol inv_mpu_core_probe (err -2)
[ 371.880003] inv_mpu6050_i2c: Unknown symbol i2c_mux_alloc (err -2)
[ 371.886235] inv_mpu6050_i2c: Unknown symbol inv_mpu_pmops (err -2)
[ 371.892499] inv_mpu6050_i2c: Unknown symbol i2c_mux_del_adapters (err -2)
[ 371.899346] inv_mpu6050_i2c: Unknown symbol i2c_mux_add_adapter (err -2)
[ 371.908395] inv_mpu6050_i2c: Unknown symbol inv_mpu_core_probe (err -2)
[ 371.915109] inv_mpu6050_i2c: Unknown symbol i2c_mux_alloc (err -2)
[ 371.921432] inv_mpu6050_i2c: Unknown symbol inv_mpu_pmops (err -2)
[ 371.927649] inv_mpu6050_i2c: Unknown symbol i2c_mux_del_adapters (err -2)
[ 371.934502] inv_mpu6050_i2c: Unknown symbol i2c_mux_add_adapter (err -2)
insmod: can't insert 'inv-mpu6050-i2c.ko': unknown symbol in module, or unknown parameter
Te problemy wynikają z faktu, że moduł inv-mpu6050-i2c posiada zależności w innych modułach. Musimy je więc jakoś załadować. Tylko, które dokładnie musimy? I czy trzeba je wszystkie po kolei ładować insmodem?
Na szczęście istnieje rozwiązanie tych dwóch problemów i nie musimy ani wiedzieć co musimy po kolei załadować i nie musimy też wydawać miliona komend, wystarczy dokładnie jedna komenda! Naszym rozwiązaniem problemu jest program modprobe. Wykonaj następującą komendę:
modprobe inv-mpu6050-i2c.ko
I tym razem sukces! Sprawdź teraz czy katalog z plikami akcelerometra istnieje:
# BBB
ls /sys/bus/i2c/devices/2-0068/iio\:device0/
# RPi4
ls /sys/bus/i2c/devices/1-0068/iio\:device0/
Powinna wyświetlić się zawartość znana Tobie z poprzedniej lekcji. Czyli sukces.
Jak chcesz zobaczyć jeszcze jedną sztuczkę to możesz zrestartować swoją płytkę i załaduj sterownik do MPU6050 będąc w dowolnym katalogu:
cd /
modprobe inv-mpu6050-i2c.ko
I to też się udało! W dociekliwych głowach być może pojawiło się pytanie: „Ale skąd ten modprobe wie co ma załadować i czemu nie muszę mu podawać dokładnej ścieżki do modułu?”.
Istnieje plik modules.dep znajdujący się w /lib/modules/wersja_linuksa. To w tym pliku znajduje się lista modułów i zależności pomiędzy nimi. Plik ten jest generowany podczas instalacji modułów za pomocą programu depmod. Jeśli miałbyś kiedyś potrzebę wygenerowania zależności pomiędzy modułami to możesz wykonać komendę:
depmod -b /ścieżka/do/rootfs -w wersja_linuksa
W naszym przypadku by to wyglądało tak:
depmod -b /media/user/rootfs -w 5.14.1
Sprawdzanie listy załadowanych modułów
Sprawdzanie listy załadowanych modułów jest bardzo proste. Służy do tego komenda lsmod. Po wykonaniu tej komendy powinieneś zobaczyć takie wyjście:
Module Size Used by Not tainted
inv_mpu6050_i2c 16384 0
inv_mpu6050 28672 2 inv_mpu6050_i2c
industrialio_triggered_buffer 16384 1 inv_mpu6050
kfifo_buf 16384 1 industrialio_triggered_buffer
i2c_mux 16384 1 inv_mpu6050_i2c
industrialio 61440 3 inv_mpu6050,industrialio_triggered_buffer,kfifo_buf
lsmod pokazuje nazwy załadowanych modułów, ich rozmiary oraz przez ile i jakie moduły są używane. „Not tainted” oznacza, że wszystko jest zrobione tak jak Linus nakazał czyli wszystkie modułu używają licencji GPL oraz używane moduły zostały zbudowane dla obecnie używanej wersji kernela. W przypadku Linuksa słowo tainted czyli skażony będzie oznaczać, że coś jest nie tak albo, że coś nie może być sprawdzone.
Usuwanie modułu
Gdy już nie chcemy używać danego modułu możemy go usunąć poleceniem rmmod. Zwróć uwagę, że nie możemy usunąć modułu, który jest używany przez inny moduł. Czyli w naszym przykładzie możemy wykonać operacje:
rmmod inv_mpu6050_i2c
ponieważ ten moduł nie jest używany przez żaden inny, ale nie możemy wykonać np. tego:
rmmod industrialio
ponieważ ten moduł jest używany przez aż 3 inne moduły.
Możesz również użyć polecenia modprobe do usunięcia modułu:
modprobe -r inv_mpu6050_i2c
To polecenie usunie pojedynczy moduł, jeśli chciałbyś usunąć dany moduł wraz z modułami, które go używają wykonaj polecenie:
Device-tree, co było wspominane na początku, jest plikiem opisującym konfigurację sprzętową. Jest ono ładowane do pamięci podczas startowania systemu operacyjnego. Warto jeszcze zwrócić uwagę, że device-tree nie jest używane w przypadku każdej architektury. Np. w przypadku architektury x86/x86_64 nie uświadczysz pracy z device-tree. Natomiast w przypadku procesorów z rodziny ARM czy ARM64 jest używane właściwie zawsze.
Istotne jest jeszcze pytanie co umieszczamy w device-tree? Czy umieszczamy tam wszystkie urządzenia podłączone do płytki? Odpowiedź brzmi nie, w device-tree umieszczamy tylko urządzenie, które nie posiadają mechanizmu wykrywania. Czyli mówiąc obrazowo, będziemy tam umieszczać urządzenia komunikujące się po interfejsach takich jak I2C, SPI czy 1Wire, ale nie będziemy tam umieszczać urządzeń używających np. USB ponieważ te posiadają mechanizm hotplug.
Składnia
Device-tree składa się z węzłów(node’ów). Każdy węzeł może posiadać swoje właściwości(properties) i może zawierać kolejny węzeł potomny, w przypadku gdy węzeł posiada jakieś właściwości i węzły potomne to właściwości muszą być zdefiniowane przed tymi węzłami. Każdy węzeł posiada tylko jednego rodzica za wyjątkiem węzła root, który to nie posiada żadnego rodzica. Dodatkowo węzły mogą mogą się do siebie wzajemnie odwoływać(przez tę właściwość device-tree w sensie matematycznym jest grafem a acyklicznym, a nie drzewem, ale to taka ciekawostka). Kod device-tree przechowuje się w plikach dts, a nagłówki device-tree w plikach dtsi. No dobra, tyle teorii, a jak to wygląda?
W źródłach kernela istnieje pliki arch/arc/boot/dts/skeleton.dtsi, który dobrze prezentuje jak wygląda takie device-tree w ogólności:
Nie wygląda to jakoś strasznie chyba. Przynajmniej w takiej małej skali. Oczywiści device-tree dla BBB czy RPi4 jest znacznie bardziej złożone i ich device-tree te składają się z kilku plików.
W niektórych linijkach możesz zobaczyć odwołania typu &core_clk i &core_intc. Są to właśnie odwołania do innych węzłów. core_clk oraz core_intc są etykietami i definiujemy je tak:
etykieta: węzeł {
…
};
W praktyce to może wyglądać np. tak:
core_intc: interrupt_controller {
...
};
Do zdefiniowanych węzłów możesz się nie tylko odwoływać, możesz je również modyfikować np. poprzez dodawanie do nich kolejnych węzłów potomnych. Pokażmy to może na przykładzie magistrali I2C. Mamy zdefiniowaną magistralę I2C w device-tree:
i2c1: i2c@48000000 {
…
}
Powyższy kod może być np. w pliku dtsi, który jest współdzielony przez wiele urządzeń bazujących na danej architekturze. Załóżmy, że chcemy dodać jakieś urządzenie na naszej płytce, zatem byśmy załadowali ten plik dtsi, a w naszym pliku dts byśmy dodali wpis:
&i2c1 {
nasze_urządzenie@10 {
...
}
}
Będziemy używać tego typu zapisu w dalszej części lekcji.
Kompilacja
Kompilacja device-tree polega na przetworzeniu pliku dts to postaci pliku binarnego(pliku dtb- device-tree blob), który może być później załadowany do pamięci i użyty przez system operacyjny.
Do kompilacji device-tree używamy programu dtc. Nie będziemy go używać bezpośrednio, choć jego użycie jest bardzo proste:
dtc -O dtb -o output_file.dtb input_file.dts
Z ciekawych rzeczy to kompilacja device-tree jest odwracalna. Tak, możemy sobie podkraść device-tree z jakiegoś urządzenia i sprawdzić jego konfiguracje, służy do tego komenda:
Nie będziemy używać tych komend, pozwolimy kernelowym Makefile’om wykonać za nas całą robotę.
Bindingi
Bindingi opisują sposób w jaki urządzenie powinno być zdefiniowane w device-tree. Bindingi są dostępne w kodzie kernela w katalogu Documentation/devicetree/bindings. Opisy bindingów są obecnie zapisywane w formacie YAML, wcześniej były to zwykłe pliki tekstowe.
Będziemy podłączać akcelerometr MPU6050. Binding dla tego urządzenia również istnieje: Documentation/devicetree/bindings/iio/imu/invensense,mpu6050.yaml W pliku tym mamy opisane jakie właściwości to urządzenie posiada, a na samym dole mamy przykład. Może to go weźmy na tapet:
Jest to węzeł potomny węzła i2c, wiemy zatem, że będziemy musieli podpiąć nasz akcelerometr pod jedną z dostępnych magistrali i2c. Co do nazwy to w zasadzie może być ona dowolna, ale dobrze jeśli odnosi się ona do definiowanego urządzenia. Liczba po @ nie definiuje adresu urządzenia, jest to część nazwy, ale wg ogólnie przyjętej konwencji po @ stawiamy adres urządzenia. W tym przypadku jest to domyślny adres MPU6050 czyli 0x68.
Następnie mamy właściwość „compatible”. Jest to właściwość dzięki której Linux wie za pomocą którego sterownika ma obsługiwać dane urządzenie.
Kolejną właściwością jest reg, nazwa może być nieco myląca bo nie chodzi o żaden rejestr tylko o adres urządzenia na magistrali I2C. My użyjemy domyślnego adresu czyli 0x68.
interrupt-parent to chip GPIO na którym znajduje się pin GPIO do którego jest podłączony pin INT akcelerometru. Właściwość interrupts to natomiast już dokładny pin na tym chipie oraz informacja na jakie przerwanie sterownik ma reagować. Trochę to zagmatwane z tymi przerwaniami i chipami GPIO, ale wynika to z konstrukcji urządzeń. Zostanie to wytłumaczone na przykładzie.
Następną właściwością jest mount-matrix, jest to macierz kalibrująca pracę MPU6050. Nie będziemy tego używać.
No i na koniec mamy i2c-gate. Czym to jest? W pliku Documentation/devicetree/bindings/i2c/i2c-gate.yaml mamy taką informacje:
An i2c gate is useful to e.g. reduce the digital noise for RF tuners connectedto the i2c bus. Gates are similar to arbitrators in that you need to performsome kind of operation to access the i2c bus past the arbitrator/gate, butthere are no competing masters to consider for gates and therefore there isno arbitration happening for gates.
Co to znaczy? Jeśli dobrze rozumiem to i2c-gate jest urządzeniem, które w jakiś sposób blokuje bezpośredni dostęp do magistrali I2C, aby się do niej dostać trzeba wykonać jakiś zestaw operacji, który zostanie zaakceptowany przez bramkę, dopiero gdy bramka zaakceptuje nasze operacje MPU6050 będzie mogło przesłać dane po magistrali. Jakieś to dziwne jest dlatego nie będziemy tego używać 🙂
Dodawanie urządzenia do device-tree
Uzbrojeni w wiedzę z poprzednich sekcji możemy przejść w końcu do dodania własnego urządzenia w systemie. Niestety, użytkownicy QEMU znowu będą zawiedzeni ponieważ ze względu na brak możliwości podłączenia czegokolwiek z oczywistych względów nie będą w stanie wykonać tego ćwiczenia.
BeagleBone Black
W przypadku BBB mamy wyprowadzoną magistralę I2C2, do tej magistrali musimy podłączyć MPU6050. Device-tree dla BBB składa się z wielu pliku dtsi oraz pliku, który to zbiera w całość o nazwie am335x-boneblack.dts znajdującego się w katalogu arch/arm/boot/dts/. Otwórz ten plik i dodaj taki wpis na końcu tego pliku:
Jak widzimy odwołujemy się tutaj do magistrali i2c2 poprzez &i2c2 i dodajemy do niej nowy węzeł mpu6050. W właściwości compatible podaliśmy nazwę producenta i model urządzenia, dzięki temu Linux powiąże nasz wpis z odpowiednim sterownikiem. W reg podaliśmy adres MPU6050 na magistrali I2C2 czyli 0x68. Dwa pozostałe wpisy nie są potrzebne, ale może na przykładzie wytłumaczymy o co chodzi. BBB posiada kilka chipów(modułów) GPIO, każdy z nich posiada 32 piny. Skoro na pinoutcie BBB widzimy np. pin GPIO_117 to skąd się wzięła ta liczba skoro każdy chip ma tylko 32 nóżki? Numer pinu GPIO obliczamy w taki sposób:
numer_chipu * 32 + numer_pinu
W powyższym przykładzie używamy pinu 21 na chipie gpio3 czyli:
3 * 32 + 21 = 117
Zatem jeśli chciałbyś obsługiwać przerwania pochodzące od MPU6050 musisz podłączyć pin INT akcelerometru do pinu GPIO_117 BBB.
Wpis IRQ_TYPE_EDGE_RISING oznacza, że przerwanie ma być generowane tylko w wyniku reakcji na zbocze narastające sygnału.
Device-tree jest gotowe, ale nie przebudowywuj jeszcze kernela.
Raspberry Pi 4
W przypadku RPi4 mamy wyprowadzoną na piny płytki magistralę I2C1 i to do niej podłączymy MPU6050. Device-tree RPi4 składa się oczywiście z wielu plików dtsi oraz pliku bcm2711-rpi-4-b.dts znajdującego się w katalogu arch/arm64/boot/dts/broadcom. Otwórz ten plik i dodaj tam taki wpis:
Jak widzimy odwołujemy się tutaj do magistrali i2c1 poprzez &i2c1 i dodajemy do niej nowy węzeł mpu6050. W właściwości compatible podaliśmy nazwę producenta i model urządzenia, dzięki temu Linux powiąże nasz wpis z odpowiednim sterownikiem. W reg podaliśmy adres MPU6050 na magistrali I2C1 czyli 0x68. Dwa pozostałe wpisy opisują obsługę przerwań, wytłumaczymy na tym przykładzie o co chodziło z tymi kontrolerami przerwań w sekcji o bindingach. RPi4 posiada jeden chip GPIO więc nie mamy problemy z jego wyborem. Następnie wskazujemy numer nóżki, w naszym przykładzie będzie to pin nr 4. Zatem jeśli chciałbyś otrzymywać przerwania od MPU6050 musisz podłączyć pin INT akcelerometra z pinem GPIO4 RPi4. IRQ_TYPE_EDGE_RISING oznacza, że przerwanie ma być generowane w reakcji na zbocze narastające sygnału.
Device-tree jest gotowe, ale nie buduj jeszcze kernela.
Konfiguracja kernela
Mamy device-tree, ale nie mamy jeszcze sterownika, który by to obsłużył w naszym kernelu. Dodaj więc odpowiednie sterowniki w swoim kernelu.
BeagleBone Black
Uruchom menuconfig i dodaj następujące opcje jako wkompilowane w kernel:
CONFIG_IIO
CONFIG_I2C_MUX
CONFIG_INV_MPU6050_I2C
Dla przypomnienia, tryb wyszukiwania uruchamiasz za pomocą klawisza /.
Teraz możesz przebudować swój kernel i wgrać nowozbudowane device-tree i kernel na kartę pamięci.
Raspberry Pi 4
Uruchom menuconfig i dodaj następujące opcje jak wkompilowane w kernel:
CONFIG_I2C_CHARDEV
CONFIG_I2C_BCM2835
CONFIG_I2C_BRCMSTB
CONFIG_IIO
CONFIG_I2C_MUX
CONFIG_INV_MPU6050_I2C
Dla przypomnienia, tryb wyszukiwania uruchamiasz za pomocą klawisza /.
Teraz możesz przebudować swój kernel i wgrać nowozbudowane device-tree i kernel na kartę pamięci.
Podłączenie
Podłącz MPU6050 do wyprowadzeń magistrali I2C.
BeagleBone Black
Po pierwsze MPU6050 podłącz do napięcia 3.3V czyli np. do pinu P9_3.
W przypadku BBB magistrala I2C jest wyprowadzona na pinach P19_19(linia SCL, zegar) oraz P9_20(linia SDA, dane):
Pinout BeagleBone Black
Chętni mogą podłączyć jeszcze pin INT MPU6050 do pinu GPIO_117 jednak nie będziemy się tym dzisiaj zajmować.
Raspberry Pi 4
Przede wszystkim podłącz MPU6050 do napięcia 3.3V. W przypadku RPi4 magistrala I2C jest wyprowadzona na pinach 3 i 5:
Pinout Raspberry Pi 4
Chętni mogą podłączyć jeszcze pin INT MPU6050 do pinu GPIO_4 jednak nie będziemy się tym dzisiaj zajmować.
Jak tego użyć w Linuksie?
Gdy już masz wszystko podłączone możesz uruchomić swoją płytkę. Zaloguj się do systemu, przejdź do katalogu z plikami urządzenia:
# BBB
cd /sys/bus/i2c/devices/2-0068/iio:device0/
# RPi4
cd /sys/bus/i2c/devices/1-0068/iio:device0/
Jak było wspomniane w poprzedniej lekcji, urządzenia podłączone do odpowiedniej magistrali są widoczne w katalogu odpowiadającej tej magistrali.
Wewnątrz tego katalogu znajduje się kilkanaście plików, dla nas najbardziej interesujące są pliki in_accel_[xyz]_raw oraz in_angvel_[xyz]_raw. To one zawierają informacje zbierane przez akcelerometr i żyroskop czyli przyspieszenie i prędkość kątową. Możesz sprawdzić jeden z plików np.:
cat in_accel_x_raw
A następnie zacząć obracać MPU6050 ciągle sprawdzając zawartość tego pliku. Pownieneś widzieć, że jego zawartość ciągle się zmienia.
Brawo! Właśnie dodałeś obsługę urządzenia do kernela Linuksa za pomocą device-tree!
Jako pracę domową możesz się zastanowić jak zmodyfikować device-tree tak aby dioda podłączona w poprzedniej lekcji była obsługiwana przez sterowniki do obsługi LEDów.
Reprezentacja device-tree w systemie
Device-tree można również podejrzeć w katalogu /proc/devicetree. W tym przypadku nie ma ono formy tekstowej tylko na jego podstawie jest utworzona odpowiednia struktura katalogów. Możesz zapoznać się z tym katalogiem.
W tej lekcji zapoznamy się ze sposobami komunikacji ze sprzętem. W Linuksie, jak w każdym innym systemie operacyjnym, za interakcje ze sprzętem odpowiadają sterowniki. Nie będziemy się zajmować tym jak implementować sterowniki, ale tym jak ich używać.
Rodzaje urządzeń w Linuksie
W Linuksie wyróżniamy trzy typu urządzeń:
Znakowe(character devices)- są to urządzenia, które przesyłają ciąg bajtów. Jednym z przykładowych urządzeń znakowych jest UART, który dosyć intensywnie używamy w naszych lekcjach. Ich reprezentacje są widoczne w katalogu /dev w postaci plików
Blokowe- są to urządzenia pamięci masowej np. dyski, pendrive’y czy używane przez nas karty SD. Ich reprezentacje są widoczne w katalogu /dev w postaci plików
Sieciowe- urządzenie przesyłające i odbierające dane po sieci. Często można się spotkać ze stwierdzeniem odnośnie systemów UNIXowych, że wszystko to plik. Nie do końca jest to prawda, urządzenia sieciowe nie są reprezentowane jako pliki, ale jako interfejsy i są one widoczne przy użyciu komend takich jak ifconfig lub ip
Urządzenia znakowe
Z urządzeniami znakowymi możemy się komunikować za pomocą funkcji biblioteki standardowej read() oraz write() co w konsoli przekłada się na polecenia cat(do czytania pliku) i echo(do zapisu do pliku). Aby się przekonać się, że tak jest możesz wykonać prosty eksperyment. Podłącz swoją płytkę do komputera, ale nie uruchamiaj screena. Otwórz dwa okna terminala. W pierwszym wydaj komendę:
sudo cat /dev/ttyUSB0
W drugim zaloguj się najpierw na konto roota, a następnie wydaj komendy:
sudo su # zaloguj się na konto roota na komputerze
echo root > /dev/ttyUSB0 # zaloguj się do systemu na płytce
echo uname -a > /dev/ttyUSB0 # sprawdź wersje systemu
W pierwszym oknie po zalogowaniu się do systemu powinieneś zobaczyć, że pojawił się prompt czyli znak #, a po wydaniu drugiej komendy powinieneś zobaczyć wersje systemu, w przypadku RPi4 powinno to być coś podobnego do:
Linux buildroot 5.10.60-rpi4-aarch64-v1.0+ #4 SMP PREEMPT Sat Sep 18 21:08:04 CEST 2021 aarch64 GNU/Linux
Urządzenia te są oznaczone literą „c” w wyjściu komendy ls:
ls -l
crw------- 1 root root 4, 64 Jan 1 00:01 ttyS0
Urządzenia blokowe
Z tymi urządzeniami rzadko komunikujemy się w sposób bezpośredni choć użytkownicy BBB oraz RPi4 mieli szansę na taką interakcję podczas przygotowania swojej karty uSD. Do bezpośrednich operacji na urządzeniach blokowych należy formatowanie, tworzenie nowych partycji, ustawianie nowego systemu plików oraz montowanie. Gdy urządzenie blokowe jest podmontowane i wykonujemy operacje na plikach nasza interakcja z urządzeniem nie jest bezpośrednia.
Urządzenia te są oznaczone literą „b” w wyjściu komendy ls:
ls -l
brw------- 1 root root 179, 0 Jan 1 00:00 mmcblk0
Urządzenia sieciowe
Interakcja z tymi urządzeniami zwykle odbywa się za pomocą programów takich jak ifconfig czy ip i z reguły nie są to częste interakcje ponieważ gdy raz skonfigurujemy sieć nie potrzebujemy jej konfigurować przy każdym uruchomieniu. Później gdy np. piszemy program komunikujący się po sieci nie wskazujemy interfejsu, który ma zostać użyty, zakładamy, że system ogarnie cały routing i tym podobne rzeczy, my wskazujemy z kim chcemy się komunikować. Nie mniej istnieje możliwość wymuszenia użycia danego interfejsu sieciowego przez program, trzeba do tego wykorzystać funkcje ioctl i parametr SIOCGIFHWADDR.
A co z urządzeniami, które nie pasują do żadnej z tej kategorii?
Jeśli bawiłeś się choć trochę jakimiś elektronicznymi elementami jak np. najprostsze diody i przyciski czy wszelkiego rodzaju czujniki czy sterowniki, które komunikują się przez GPIO, I2C, SPI czy 1Wire możesz się zastanawiać co z takimi urządzeniami. Dane w tych urządzeniach są dostępne w rejestrach, które chcemy odczytywać w sposób swobodny więc nie są to ewidentnie urządzenia znakowe, które przesyłają ciąg bajtów. Ewidentnie nie są to też urządzenia blokowe ani sieciowe więc jak tego używać w Linuksie?
Otóż z reguły takie urządzenia są reprezentowane poprzez urządzenia znakowe i mamy następnie dwa sposoby komunikacji z nimi:
Za pomocą funkcji ioctl(), jest to obecnie odradzane podejście
Za pomocą sysfs czyli plików w katalogu /sys. Aktualnie jest to preferowane podejście, może ono jednak wymagać implementacji własnego sterownika jeśli chcemy pracować z jakimś mało popularnym urządzeniem
ioctl() coraz bardziej przechodzi do przeszłości dlatego też nie będziemy się nim zajmować w tej lekcji. Komunikacja z urządzeniami zostanie przedstawiona za pomocą diod LED.
Czym jest sysfs?
sysfs to wirtualny system plików. Wirtualny w tym przypadku oznacza, że są to pliki tworzone podczas pracy systemu. Pliki obecne w sysfs nie są częścią rootfsa.
sysfs zawiera reprezentacje obiektów kernela(ang. kernel objects), atrybutów tych obiektów oraz powiązań między nimi. Obiekty będą reprezentowane przez katalogi, a atrybuty przez pliki. Obiektem kernela może być np. urządzenie, a atrybutem zawartość danego rejestru tego urządzenia.
Zerkając w katalog /sys zobaczysz kilka katalogów, w praktyce nas najbardziej będą interesować trzy katalogi:
bus/- katalog zawierający reprezentacje dostępnych magistrali i urządzeń podłączonych do nich
class/- katalog agregujący urządzenia w klasy bez względu na ich interfejs komunikacyjny, przykładowo moglibyśmy mieć klasę termometr do której należałyby dwa różne termometry z czego jeden używał by do komunikacji interfejsu 1Wire, a drugi SPI
devices/- katalog zawierający informacje o podłączonych urządzeniach
Podłączenie
Niestety użytkownicy QEMU nie będą mogli przejść części praktycznej ze względu na brak możliwości fizycznego podłączenia czegokolwiek.
BeagleBone Black
Podłącz diodę LED do BBB poprzez pin oznaczony jako GPIO_48:
Pamiętaj o użyciu rezystora podczas podłączenia diody LED.
GPIO w kernelu
Aby móc obsługiwać diody musimy uruchomić wsparcie dla GPIO w kernelu. Domyślnie w przypdaku BBB oraz RPi4 wsparcie dla GPIO powinno być uruchomione, ale dla pewności sprawdźmy to, przy okazji dowiemy się jak konfigurować kernel Linuksa z poziomu Buildroota. Przejdź do katalogu Buildroot i wydaj komendę:
make linux-menuconfig
Sprawdź czy są zaznaczone opcje CONFIG_GPIOLIB oraz CONFIG_GPIO_SYSFS. Jeśli nie są to zaznacz je jako wkompilowane w kernel. Dla przypomnienia możesz użyć klawisza „/” do włączenia trybu wyszukiwania. Przebuduj swój kernel:
make
A następnie skopiuj obraz kernela oraz plik device-tree na kartę pamięci z katalogu output/images.
Gdy już masz tak przygotowany kernel uruchom swoją płytkę i wykonaj następujące komendy:
# BBB i RPi4
cd /sys/class/gpio
# BBB
echo 48 > export
# RPi4
echo 23 > export
W ten sposób właśnie aktywowałeś dany pin GPIO w kernelu. Przejdź do nowopowstałego katalogu:
# BBB
cd gpio48
# RPi4
cd gpio23
Wewnątrz tego katalogu jest kilka plików(atrybutów). Na ten moment nas interesują pliki direction czyli czy dany pin jest wejściem lub wyjściem oraz value czyli stan pinu. Domyślnie piny są ustawione jako wejście(in), my pracujemy z diodami więc chcemy aby piny były wyjściami, zatem wykonaj następującą komendę:
echo out > direction
A teraz możemy włączać i wyłączać diodę:
echo 1 > value
echo 0 > value
Brawo! Właśnie ogarnąłeś jak komunikować się ze sterownikami w Linuksie. W przypadku innych urządzeń będzie to wyglądać podobnie choć wiadomo, obsługa zawsze się będzie nieznacznie różnić ze względu na charakterystykę danego urządzenia czy klasy urządzeń.
Jako pracę domową możesz się zapoznać z obsługą diod LED, które są dostępne na twojej płytce. W przypadku BBB chodzi mi o te niebieskie diody znajdujące się przy gnieździe ethernetowym, a w przypadku RPi4 o czerwoną i zieloną diodę przy gnieździe USB-C. Ich reprezentacja znajduje się w katalogu /sys/class/leds.
Uwaga dla użytkowników BBB, wydaje się, że nowsze wersje kernela(5.x) mają jakiś problem z obsługą GPIO. Buildroot używa kernela 4.19 dla BBB i w tej wersji wygląda, że wszystko działa prawidłowo. Możliwe, że wkradł się jakiś błąd do kodu pomiędzy tymi wersjami.
W tej lekcji zapoznamy się z tym co odróżnia poszczególne dystrybucje od siebie czyli z rootfsem oraz z narzędziami służącymi do jego przygotowania.
Czym jest rootfs?
Włącz konsolę na swoim komputerze i wykonaj następującą komendę:
ls /
Komenda ta wyświetla wszystkie katalogi na twoim komputerze. Ta komenda chyba najlepiej obrazuje czym jest rootfs- jest to system plików o konkretnej strukturze. W najprostszej postaci na rootfs będą się składać programy oraz pliki konfiguracyjne niezbędne do działania systemu.
Teraz pojawia się pytanie jak zbudować taki rootfs? Możemy oczywiście przebudowywać wszystkie programy ręcznie, stworzyć pliki konfiguracyjne, ułożyć to wszystko w odpowiednią strukturę i musimy jeszcze pamiętać aby każdy plik miał odpowiednie prawa dostępu. Generalnie sporo roboty, a my jesteśmy leniwi jak to rasowi programiści. Dlatego też do tworzenia rootfs’ów korzysta się z narzędzi zwanych buildsystemami.
Czym jest buildsystem?
Buildsystem to narzędzie umożliwiające nam skonfigurowanie i przebudowanie całego systemu w przystępny sposób. Dzięki buildsystemowi możemy przebudować cały rootfs, ale nie tylko, wiele buildsystemów umożliwia również zbudowanie:
toolchaina, który my pobieraliśmy
bootloadera, którego kod pobieraliśmy i sami budowaliśmy
kernela, który również sami budowaliśmy
Czyli buildsystem umożliwia nam zbudowanie wszystkiego nie mając właściwie nic.
Na rynku jest dostępnych kilka rozwiązań, w poważnych komercyjnych zastosowaniach Yocto(a właściwie The Yocto Project) wydaję się być najpopularniejsze, ale jest również dosyć złożone i prawdę mówiąc w momencie pisania kursu sam niezbyt je ogarniam. Dlatego też nie będziemy się nim zajmować. Innym popularnym buildsystemem jest Buildroot. Bardzo dobrze nadaje się on do tworzenia prostych systemów. Jego dodatkową zaletą jest prostota jego konfiguracji, jest ona bardzo zbliżona do konfiguracji kernela Linuksowego- jest dostępny menuconfig. To właśnie go będziemy używać do budowania naszego Linuksa.
Budowanie rootfs
Drobna uwaga- proces konfiguracji w tym przypadku jest bardzo zbliżony dla wszystkich trzech platform dlatego też rozróżnienie nastąpi dopiero podczas uruchamiania.
Oczywiście musimy najpierw pobrać nasz buildsystem, możesz pobrać wersję stabilną dostępną na stronie Buildroota lub możesz pobrać wersję używaną przeze mnie:
wget https://buildroot.org/downloads/buildroot-2021.02.4.tar.gz
tar xf buildroot-2021.02.4.tar.gz
Przejdź do otrzymanego katalogu. Na samym początku, podobnie jak w przypadku kernela musimy określić domyślną konfigurację dla naszej platformy:
# dla BBB
make beaglebone_defconfig
# dla RPi4
make raspberrypi4_64_defconfig
# dla QEMU versatilepb:
make qemu_arm_versatile_defconfig
Zwróć uwagę, że tym razem nie ustawiamy ani zmiennej ARCH ani CROSS_COMPILE, Buildroot sam ogarnia co musi być ustawione.
Teraz możemy przejść do konfiguracji. Uruchom konfigurator znanym Ci już poleceniem:
make menuconfig
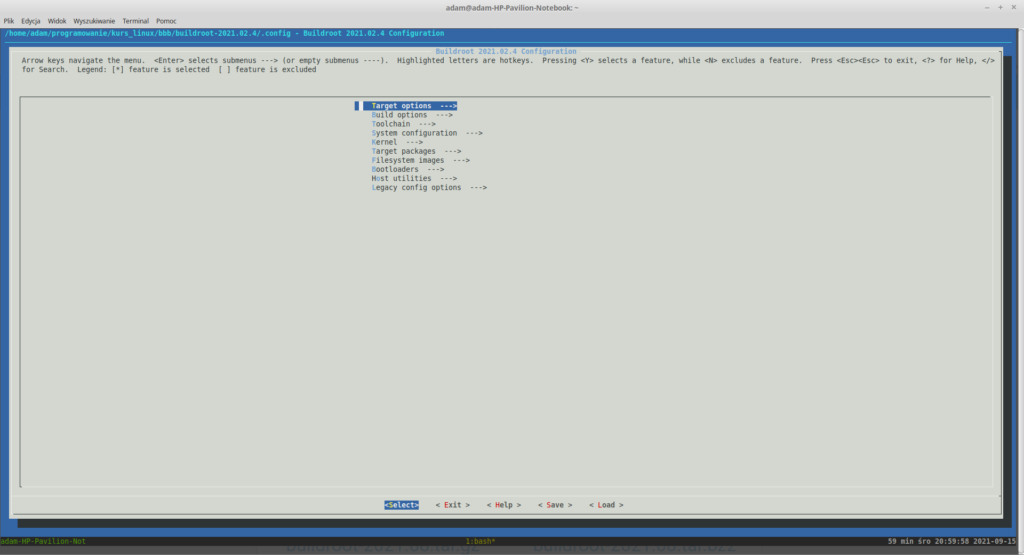
Powinieneś zobaczyć widok przypominający to co było widoczne w przypadku Linuksa:
Buildroot menuconfig
Może kilka słów o tym co będziemy chcieli zbudować:
Toolchain- moglibyśmy użyć toolchaina, który był używany do przebudowania kernela, ale zbudujemy go w celach instruktażowych
Kernel + device-tree- w zasadzie już je mamy dla każdej platformy, ale dla celów demonstracyjnych również je zbudujemy
rootfs- czyli to czego na brakuje do uruchomienia naszego Linuksa
Odpuścimy sobie budowanie bootloaderów.
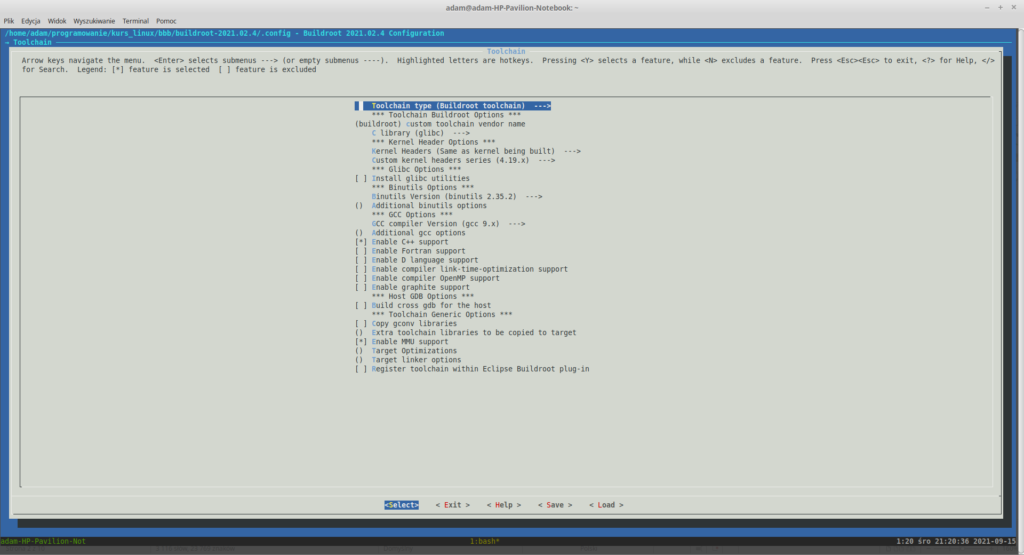
No to zaczynamy, najpierw skonfigurujmy toolchain, jak się zapewne domyślasz wybierz opcję Toolchain w menuconfigu. Pojawiło się kilka opcji, po pierwsze ustaw opcję „C Library” na glibc. Tutaj jeszcze drobna uwaga odnośnie tego jaką bibliotekę wybrać. Mamy do wyboru biblioteki uClibc-ng, musl oraz glibc:
uClibc-ng jest forkiem uClibca, która została stworzona dla systemu uCLinux czyli Linuksa, który był uruchamiany na urządzeniach bez jednostki zarządzającej pamięcią(popularnie zwane MMU, memory management unit) czyli na mikrokontrolerach, z czasem została ona dostosowana do pracy z normalnym Linuksem
musl jest biblioteką przystosowaną do pracy z urządzeniami o niewielkiej pamięci RAM, jako granicę często się podaje 32MB pamięci RAM
glibc jest biblioteką dobrze znaną z komputerów, implementuje ona najwięcej elementów standardu POSIX
Ze względu, że każda z użytych platform ma więcej niż 32MB RAMu użyjemy glibc.
Ostatnią opcją, która nas interesuje jest wsparcie dla języka C++, zaznacz więc opcje „Enable C++ support”. Twoja konfiguracja powinna wyglądać następująco:
Konfiguracja toolchaina
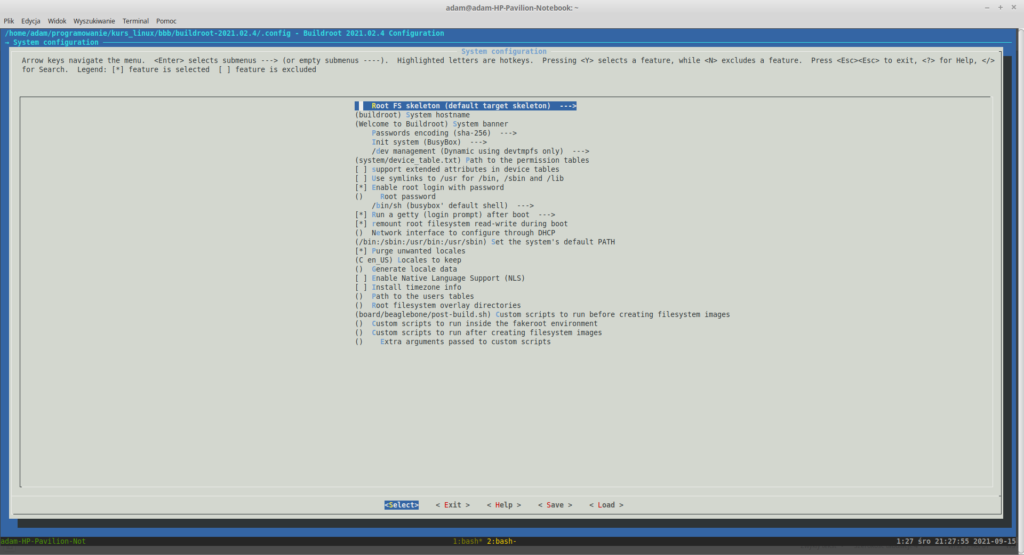
Wróć do głównego menu. Następnie przejdź do „System configuration”. Tutaj możesz zmienić nazwę swojego hosta, baner powitalny czy ustawić hasło dla roota. Możesz te opcje skonfigurować dowolnie. Na samym dole są dwie opcje: „Custom scripts to run after creating filesystem images” oraz „Extra arguments passed to custom scripts”. Ustaw je tak aby były puste. Usuwamy te opcje ponieważ nie jesteśmy zainteresowani generowaniem obrazów kart SD. Na koniec twoja konfiguracja powinna wyglądać mniej więcej tak:
System configuration
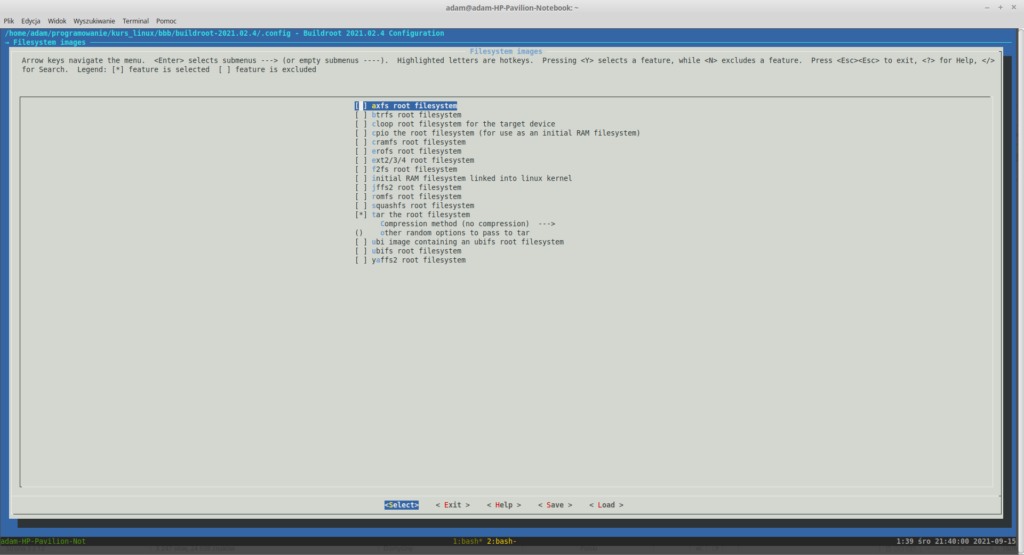
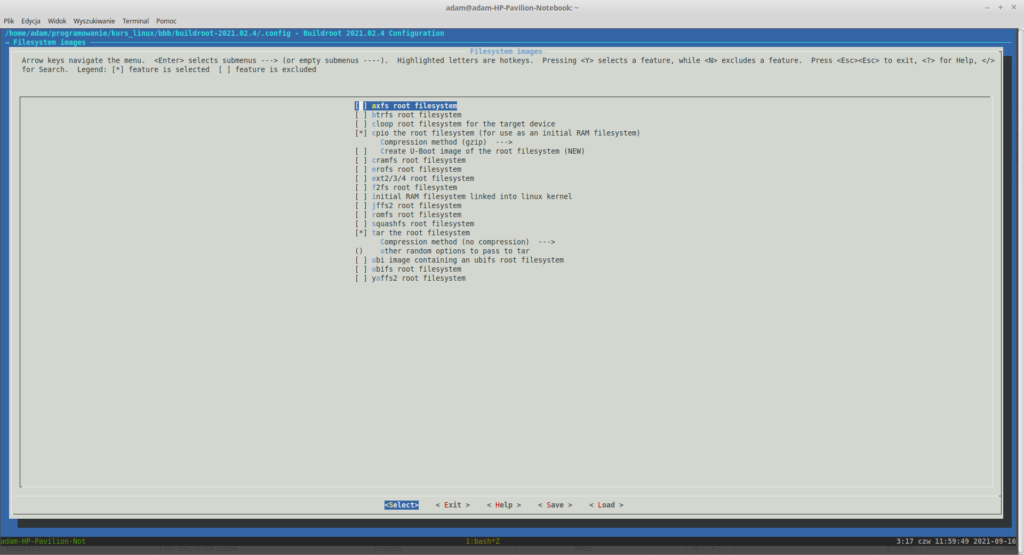
Ponownie wróć do głównego menu i wybierz „Filesystem images”. Spośród wszystkich opcji zaznaczona powinna zostać jedynie „tar the root filesystem”. Teoretycznie mogłaby nas interesować opcja „ext2/3/4 root filesystem”, która to generuje obraz dysku, który mógłby zostać podmontowany później do QEMU jednak przez pomieszanie z poplątaniem megabajtów z mibibajtami ciężko jest ustalić prawidłowy rozmiar obrazu dysku dla QEMU dla modeli ARMowych, obejdziemy ten problem “ręcznie”. Na koniec konfiguracja systemów plików powinna wyglądać tak:
Konfiguracja systemu plików
Ponownie wróć do głównego menu i przejdź do sekcji „Bootloaders” i odznacz wszystkie opcje jeśli jakaś jest zaznaczona.
Dla jasności, w przypadku kernela użyjemy domyślnych ustawień dlatego nie wchodziliśmy do tej sekcji.
Na koniec możesz wrócić do głównego menu i przejść do „Target packages”. To tam znajdują się pakiety, które możesz dodać do swojej dystrybucji, możesz nawet dodać gry.
Gdy wszystkie ustawienia są gotowe wyjdź z menuconfiga, oczywiście pamiętaj aby zapisać zmiany w konfiguracji podczas wychodzenia. Teraz możesz zbudować wszystko za pomocą komendy:
make
Proces budowania powinien potrwać jakieś 30-40 minut, no chyba, że masz nieco starszy komputer.
Pliki wynikowe będą dostępne w katalogu output/images. Będą się tam znajdować pliki dtb(czyli nasze device-tree), obrazy kernela(zImage lub Image) oraz paczki z systemami plików o nazwie rootfs.tar.
Zwróć uwagę na brak parametru -j w wywołaniu komendy make. Domyślnie Buildroot sam ogarnia ile wątków budowania uruchomić w danym momencie. Jeśli jednak chciałbyś z jakiś względów ustawić jakąś konkretną liczbę wątków budujących to zainteresuj się opcją BR2_JLEVEL.
BeagleBone Black
Bootloader jest już skonfigurowany dlatego też jedyne co musimy zrobić to dodanie naszego rootfsa na kartę pamięci. Aby to zrobić podłącz swoją kartę uSD do komputera, a następnie przejdź do katalogu z obrazami wynikowymi i rozpakuj wygenerowaną paczkę rootfs.tar na odpowiednią partycję:
cd output/images
sudo tar xf rootfs.tar -C /media/user/rootfs
sync # tę komendę wykonaj aby się upewnić, że wszystkie pliki zostały zapisane na karcie
umount /media/user/* # odmontuj kartę
Teraz umieść kartę w BBB, podłącz BBB do komputera za pomocą konwertera UART-USB, uruchom screena i uruchom BBB. Ponownie ujrzysz dużo logów, ale tym razem czeka Cię miła niespodzianka- system pyta się o użytkownika. Wpisz root. Brawo! Właśnie zalogowałeś się do swojego pierwszego własnoręcznie zbudowanego Linuksa! Jako zadanie dodatkowe możesz przetestować device-tree i kernel wygenerowane przez Buildroota.
Raspberry Pi 4
W przypadku RPi4 mamy sytuację identyczną jak z BBB, bootloader jest już skonfigurowany i jedyne co musimy zrobić to zapisać rootfs na karcie pamięci:
cd output/images
sudo tar xf rootfs.tar -C /media/user/rootfs
sync # tę komendę wykonaj aby się upewnić, że wszystkie pliki zostały zapisane na karcie
umount /media/user/* # odmontuj kartę
Umieść kartę w RPi4, podłącz RPi4 do komputera po UARTcie, uruchom screen i włącz zasilanie. Tak! Linux się uruchomił! Pyta się o użytkownika więc wpisz root. Właśnie się zalogowałeś! Brawo Ty użytkowniku RPi4! Też możesz jako dodatkowe zadanie przetestować device-tree i kernel wygenerowane przez Buildroota.
QEMU
Aby uruchomić QEMU z naszym rootfsem musimy przygotować obraz dysku, na którym będzie rootfs i który to obraz zostanie użyty przez QEMU. Przygotuj więc taki obraz za pomocą poniższych komend:
cd output/images
# utwórz obraz dysku
dd if=/dev/zero of=rootfs.img bs=1024 count=65536
# sformatuj dysk na EXT4 i nadaj etykietę rootfs
mkfs.ext4 rootfs.img -L rootfs
# zamontuj dysk pod /mnt
sudo mount rootfs.img /mnt
# wypakuj plik na dysk
sudo tar xf rootfs.tar -C /mnt
# odmontuj dysk
sudo umount /mnt
Teraz mamy już przygotowany dysk, możemy więc uruchomić system:
Wciskasz enter i… nic, system się zawiesił na logu:
Waiting for root device /dev/sda…
Czyli wygląda jakby nie wykrywał dysku. Spróbuj uruchomić teraz QEMU z kernelem i device-tree wygenerowanym przez Buildroota.
I co tym razem się okazało? Tak, system się uruchomił! Możesz się zalogować i używać swojego systemu. Brawo!
Pojawia się pytanie czemu kernel zbudowany na poprzedniej lekcji nie działa z rootfsem. Otóż domyślna konfiguracja dla versatile’a nie ma włączonego wsparcia dla obsługi urządzeń blokowych. Jeśli chciałbyś użyć swojego kernela musisz przejść do katalogu z jego kodem źródłowym kernela, włączyć menuconfig i ustawić następujące opcje jako wkompilowane w kernel(dla przypomnienia tryb wyszukiwania włączasz klawiszem /):
CONFIG_PCI
CONFIG_PCI_VERSATILE
CONFIG_SCSI
CONFIG_SYM53C8XX_2
CONFIG_BLK_DEV_SD
CONFIG_DEVTMPFS
CONFIG_DEVTMPFS_MOUNT
Przebuduj kernel. Teraz system powinien już wystartować bez żadnych problemów.
Jeśli chcesz zbudować rootfs na architektury ARM64 lub x86_64 to użyj odpowiednio konfiguracji qemu_aarch64_virt_defconfig lub qemu_x86_64_defconfig.
Initramfs
Initramfs to mały system plików, który może zostać załadowany do pamięci RAM podczas startowania systemu. Można taki system plików można wykorzystać do szybkiego uruchomienia systemu i wstępnej inicjalizacji peryferiów, a w momencie gdy dysk z docelowym rootfsem będzie dostępny to ten dysk zostanie zamontowany i użyty jako rootfs. Użycie initramfsa można traktować jako dodatkowy krok w sekwencji startowania systemu. Standardowo Initramfs ma postać archiwum cpio.gz. W przypadku użycia U-Boota, jak ma to miejsce np. w przypadku BBB, takie archiwum musi dostać jeszcze odpowiedni nagłówek.
Nasz zbudowany rootfs nie jest zbyt duży dlatego też możemy go użyć jako initramfs. Przejdź do katalogu Buildroota i włącz menuconfig. Przejdź do sekcji „Filesystem images”, włącz opcję „cpio the root filesystem (for use as an initial RAM filesystem)”, jako metodę kompersji wybierz gzip. Konfiguracja powinna wyglądać tak:
Konfiguracja systemów plików w celu zbudowania initramfs
Zapisz zmiany w konfiguracji i przebuduj ponownie system. Tym razem będzie to trwało bardzo krótko, może z jedną minutę. W katalogu output/images zostanie wygenerowany plik rootfs.cpio.gz.
W naszym przypadku różnica pomiędzy użyciem rootfsa na karcie pamięci a użyciem initramfs będzie bardzo nieznaczna. Wy możecie zauważyć dwie rzeczy:
Brak persystentności plików w przypadku initramfsu, oznacza to, że plik utworzony podczas pracy z urządzeniem zniknie wraz z jego wyłączeniem
Możesz sprawdzić punkty montowania za pomocą programu mount. Zobaczysz, że są one różne w przypadku użycia rootfsa z karty pamięci i initramfsa
BeagleBone Black
Przejdź do katalogu z obrazami. Musisz utworzyć plik z initramfsem, który będzie mógł być użyty przez U-Boota. Taki plik można uzyskać używając programu mkimage. Komenda wygląda następująco:
mkimage -A arm -O linux -T ramdisk -d rootfs.cpio.gz initramfs
Zostanie wygenerowany plik initramfs. Umieść ten plik na swojej karcie uSD na partycji kernel(czyli tam gdzie jest kernel :)), umieść kartę z powrotem w BBB, podłącz go po UARTcie do komputera i uruchom go. Przerwij proces bootowania tak aby mieć dostęp do konsoli U-Boota. Po pierwsze aby mieć pewność, że nie zostanie użyty rootfs z karty uSD musimy zmienić zmienną bootargs:
Tym razem podajemy wszystkie parametry bootz. Powinien uruchomić się system. Jak wspomniano wcześniej nie widać żadnej znaczącej różnicy na pierwszy rzut oka, ale Ty wiesz jak już sprawdzić czy używasz initramfsu.
Raspberry Pi 4
Przejdź do katalogu z obrazami, a następnie skopiuj plik rootfs.cpio.gz na kartę uSD na partycję boot. Następnie zmodyfikuj plik config.txt poprzez dodanie linii:
initramfs rootfs.cpio.gz
Brak znaku równości nie jest błędem.
Żeby mieć pewność, że nie jest używany rootfs z karty pamięci zmodyfikuj plik cmdline.txt do postaci:
console=ttyS0,115200 earlyprintk
Umieść kartę pamięci w RPi4, podłącz je do komputera i uruchom. Powinien uruchomić się system i tak samo jak w przypadku BBB na pierwszy rzut oka nie widać żadnej istotnej zmiany.
Gdy już sprawdzisz wszystko co chciałeś sprawdzić przywróć ustawienia RPi4 do poprzedniego stanu.
QEMU
Tutaj sprawa jest prosta, po prostu użyjemy odpowiedniej komendy do uruchomienia QEMU:
Tutaj korzystamy z nowego parametru -initrd, który to wskazuje na initramfs do użycia. Jak widać tym razem nie korzystamy z żadnego obrazu dysku mamy więc 100% pewności, że nasz system plików to initramfs.
Dodawanie własnych plików do rootfs
Czasami może zajść potrzeba aby dodać jakiś swój plik konfiguracyjny czy program do rootfsa. Oczywiście można by to zrobić ręcznie i samodzielnie wkleić odpowiednie pliki do rootfs na kartę pamięci, ale to jest mało poręczne, łatwo o tym zapomnieć itd.
Przypuśćmy, że chcesz dodać plik o nazwie file.conf do katalogu /etc. Aby to zrobić musisz zrobić nakładkę(po angielsku overlay) na system plików czyli przygotować interesującą Cię strukturę katalogów. Aby to zrobić utwórz katalog gdzieś poza Buildrootem i przejdź do niego:
mkdir overlay
cd overlay
Następnie utwórz to co chcesz nadpisać/dodać w oryginalnym rootfs:
I mamy już przygotowane wszystko co chcemy dodać. Przebuduj teraz Buildroota za pomocą komendy:
make BR2_ROOTFS_OVERLAY=/ścieżka/do/overlay/
Teraz po rozpakowaniu rootfsa na kartę pamięci będzie tam plik /etc/file.conf. Ta metoda zadziała dla każdego rodzaju plików, także dla skryptów czy plików binarnych.
Dodawanie własnego pakietu do Buildroota
Dodawanie plików nie zawsze też jest idealnym rozwiązaniem, czasami mamy kod, który byśmy chcieli budować razem z innymi pakietami, a na koniec umieścić zbudowany program do systemu plików.
Zacznijmy od zrobienia prostego programu, tzw. Hello World napisanego w C++. Kod źródłowy programu jest następujący:
#include <iostream>
using namespace std;
int main()
{
cout << "Hello!!!" << endl;
return 0;
}
Aby móc zrobić pakiet buildrootowy potrzebujemy mieć prostą możliwość przebudowania tego programu dlatego przygotujemy Makefie’a:
Umieść te dwa pliki w jakimś katalogu poza Buildrootem. Następnie przejdź do katalogu Buildroota. Utwórz katalog dla naszego pakietu:
mkdir package/hello
Następnie utwórz plik hello.mk wewnątrz package/helo o zawartości:
HELLO_VERSION = 1.0.0 # wersja programu
HELLO_SITE = /ścieżka/do/hello # lokalizacja kodu, może być to również lokalizacja w sieci
HELLO_SITE_METHOD = local # sposób pozyskania kodu
# komendy do budowania pakietu
define HELLO_BUILD_CMDS
$(MAKE) CXX="$(TARGET_CXX)" LD="$(TARGET_LD)" -C $(@D) all
endef
# komendy do instalacji pakietu
define HELLO_INSTALL_TARGET_CMDS
$(INSTALL) -D -m 0755 $(@D)/hello $(TARGET_DIR)/bin/hello
endef
$(eval $(generic-package))
Mamy wszystko co potrzebne do zbudowania pakietu, teraz musimy umożliwić jakoś jego wybór w menuconfigu. Aby to zrobić utwórz plik o nazwie Config.in w package/hello o następującej zawartości:
config BR2_PACKAGE_HELLO
bool "hello"
help
Application that says hello to a user
Następnie otwórz plik package/Config.in i niemalże na samym końcu przed ostatnią linijką endmenu dodaj taki wpis:
menu "My programs"
source "package/hello/Config.in"
endmenu
Teraz możesz włączyć menuconfiga i przejść do sekcji „Target packages”. Na samym dole powinna być opcja „My programs”, a po przejściu do niej będzie widoczny pakiet hello. Zaznacz go i przebuduj rootfs. Podmień rootfs na swojej karcie pamięci(w swoim obrazie dysku jeśli używasz QEMU). Po uruchomieniu urządzenia będziesz mógł wywołać komendę hello. Plik będzie się znajdować w katalogu /bin.
Wygenerowany toolchain
Toolchain zbudowany przez Buildroota znajduje się w katalogu output/host/bin. Jeśli chcesz zbudować „ręcznie” program na swoją platformę powinieneś użyć kompilatorów z tego miejsca. Ich użycie jest identyczne jak standardowego gcc/g++ na twoim komputerze z wyjątkiem tego, że mają nieco przydługie nazwy.
W 1991 Torvalds poinformował na grupie dyskusyjnej systemu Minix, że tworzy swój kernel systemy operacyjnego przeznaczonego na procesory i386 oraz i486. Kernel ten został nazwany później Linuksem. Specjalnie podkreśliłem słowo kernel aby wskazać, że Linux to tak de facto nie jest całym systemem operacyjnym tylko jego jądrem(kernelem).
Kernel to mózg systemu operacyjnego. To właśnie on odpowiada za zarządzenie zasobami, komunikację ze sprzętem oraz dostarczenie warstwy abstrakcji dla aplikacji użytkownika.
Architektura kernela Linuksa
Wyróżniamy dwie architektury kerneli systemów operacyjnych- mikrokernele oraz kernele monolityczne. W przypadku mikrokernela sam kernel odpowiada za bardzo nie wiele zadań, zazwyczaj jest to zarządzanie przydziałem procesora oraz za komunikację pomiędzy procesami. Wszelkie sterowniki nie stanowią części kernela tylko oddzielne procesy. W przypadku kernela monolitycznego kernel posiada wiele więcej funkcji oprócz szeregowania zadań i komunikacji pomiędzy procesami. Taki kernel obsługuje również komunikację z wszelkimi peryferiami sprzętowymi czy obsługę odpowiednich systemów plików.
Jaka jest różnica w działaniu tych kerneli? Dla nas najważniejsza będzie chyba stabilność systemu. W przypadku kernela monolitycznego gdy wystąpi błąd w jednym podsystemie np. w sterowniku myszki może to spowodować zawieszenie całego systemu natomiast w przypadku mikrokernela tylko moduł odpowiedzialny za pracę myszki zakończy działanie bez wpływu na resztę systemu. Kolejną cechą, którą możecie zauważyć to rozmiar kernela. Mikrokernel będzie z reguły mniejszy ze względu na niewielką ilość zadań, którą się zajmuje, kernel monolityczny będzie oczywiście odpowiednio większy.
Linux ma architekturę monolityczną.
Moduły
Wiele z części(podsystemów) kernela może zostać wkompilowana do jego obrazu lub zostać skompilowana jako moduł. Moduł to specjalny plik binarny, który może zostać włączony do kernela podczas jego pracy. Jakie są różnice pomiędzy wkompilowywaniem wszystkiego do kernela a używaniem modułów? W przypadku wkompilowywania wszystkiego do kernela nie musimy się martwić o ładowanie modułów i o potrzebne zależności niezbędne do jego działania. Wadą takiego rozwiązania może być niekiedy czas startowania systemu i ewentualnie rozmiar kernela. W takim przypadku jakakolwiek zmiana ustawień kernela będzie wymagała jego ponownej kompilacji i jego podmiany.
Co do modułów, na pewno umożliwiają one większą elastyczność pracy, możemy je ładować gdy są potrzebne i odmontowywać gdy nie są już potrzebne, przeniesienie części funkcjonalności do modułów umożliwia również zmniejszenie czasu potrzebnego do uruchomienia systemu. Używanie modułów daje nam duże pole do konfiguracji kernela bez potrzeby jego ponownej kompilacji. Wadą takiego rozwiązanie jest potrzeba spełnienia wszystkich zależności aby dany moduł mógł pracować jak np. załadowanie innych modułów od których ładowany moduł jest zależny.
Kod źródłowy kernela
Kod źródłowy kernela można pobrać ze strony kernel.org w postaci paczki tar.xz lub z repozytorium torvalds/linux dostępnego na githubie.
Z istotnych rzeczy trzeba zwrócić uwagę na dwa typy wersji wydań(release’ów) kodu Linuksa. Mamy wersję main, która cały czas żyje, do której dodawane są cały czas nowe funkcje, poprawki itd. Ta wersja kodu może nie zawsze działać. Drugim typem jest stable czyli mówiąc po polsku wersja stabilna. Do tego typu źródeł będą wchodzić tylko przetestowane zmiany dzięki czemu możemy oczekiwać, że Linux przebudowany z takich źródeł będzie działał tak jak tego chcemy(choć wiadomo, jakiś błąd może czasami przejść). W przypadku wersji stabilnej można wyróżnić jeszcze wersje LTS(Long Term Support), jest to kod danej wersji Linuksa, która jest utrzymywana przez dłuższy czas np. 3 lata.
Co do samych źródeł to nas póki co najbardziej będą interesowały katalogi arch oraz Documentation. Katalog arch zawiera pliki charakterystyczne dla danych architektur jak np. konfiguracje, a Documentation jak się pewnie domyślacie zawiera dokumentacje poszczególnych elementów Linuksa.
Konfiguracja kernela
Kernela rzadko konfiguruje się od zera, każdy wydawca SoCa, który chce wspierać Linuksa dostarcza plik defconfig do źródeł dzięki czemu mamy dostępną od ręki wiele konfiguracji dla wielu urządzeń. Aby użyć konkretnej konfiguracji musimy skorzystać z narzędzia make i wykonać komendę, która będzie wyglądać mniej więcej tak:
make ARCH=architektura CROSS_COMPILE=prefix-kompilatora- soc_defconfig
Parametr ARCH to oczywiście docelowa architektura procesora na którą budujemy kernel, a CROSS_COMPILE to przedrostek dla naszego kompilatora. Ostatni parametr to domyślna konfiguracja, której chcemy użyć. Na przykład, dla płytki BBB wywołanie takiej komendy wyglądało by następująco:
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- omap2plus_defconfig
Teraz byśmy mogli skompilować kernel i bylibyśmy w stanie uruchomić go. Ale co jeśli byśmy chcieli coś zmodyfikować np. dodać jakiś sterownik albo przeciwnie, usunąć jakiś sterownik. Kernel dostarcza narzędzie menuconfig dzięki któremu konfiguracja kernela jest stosunkowo przyjazna dla człowieka. Aby uruchomić menuconfig znów używamy polecenia make(przykład dla BBB):
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- menuconfig
Pamiętaj aby zawsze wskazywać ARCH oraz CROSS_COMPILE, inaczej może to spowodować błędy w konfiguracji, ewentualnie możesz wyeksportować te parametry jako zmienne środowiskowe.
Po wykonaniu tej komendy powinieneś ujrzeć widok podobny do tego na poniższym rysunku:
Konfigurator Linuksa
Jest tam wiele różnych opcji, od sterowników po różne kernelowe haki(sekcja na samym dole menuconfiga). Opcje mają różną formą, niektóre wymagają aby podać jakieś ustawienie tekstowo lub liczbowo, ale najpopularniejsze są chyba opcje „tristate”. Jak nazwa sama wskazuję są opcje które mogą mieć trzy stany: wkompilowany w kernel(wtedy taka opcja jest zaznaczona znakiem asterisk(*) z lewej strony), kompilowana jako moduł(wtedy taka opcja jest zaznaczona jako M z lewej strony) oraz nie używane, wtedy nie ma nic z lewej strony takiej opcji.
Czasami jesteśmy zainteresowani tylko zmianą jednej opcji, ale nie do końca wiemy gdzie się ona znajduje w strukturze w menuconfiga, w takim przypadku możemy skorzystać z wyszukiwania. Aby włączyć tryb wyszukiwania wciskamy klawisz ukośnika(/) i możemy wyszukać interesującej nas opcji.
Dalsza lektura
To tyle co trzeba wiedzieć aby przejść do kolejnego etapu tej lekcji czyli budowania własnego kernela Linuksa. Osoby głębiej zainteresowane tematyką kernela mogą rzucić okiem na książkę „Jądro Linuksa” autorstwa Roberta Love. Książka nie jest najnowsza, ale ma jedną zasadniczą zaletę- jest po polsku. Zmiany w kernelu również nie są tak głębokie aby książka ta zdeaktualizowała się całkowicie, daje ona dobry ogląd na temat tego jak działa Linux.
A teraz przechodzimy już do praktyki, dla każdej platformy została przygotowana oddzielna sekcja więc jeśli jesteś zainteresowany tylko jedną platformą możesz przeskoczyć od razu do odpowiedniej sekcji.
Zanim przejdziesz do części praktycznej przypominam aby ścieżka z kompilatorami znajdowała się w zmiennej środowiskowej PATH.
BeagleBone Black
Aby zbudować kernel trzeba mieć oczywiście jego źródła, pobierzmy je i od razu rozpakujmy:
wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.14.1.tar.xz
tar xf linux-5.14.1
cd linux-5.14.1
Teraz będąc już w katalogu z kodem możemy ustawić domyślną konfigurację dla BBB:
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- omap2plus_defconfig
W zasadzie nie musimy nic zmieniać w konfiguracji kernela, ale abyś miał pewność, że to Twój świeżo zbudowany kernel się uruchamia zmodyfikujemy opcję LOCALVERSION w menuconfig. Uruchom więc konfigurator:
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- menuconfig
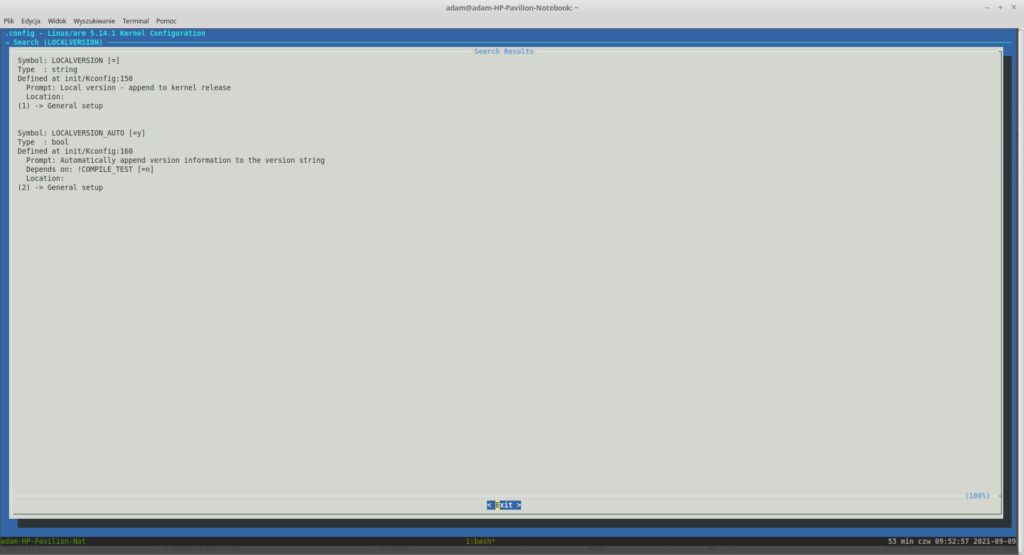
Włącz tryb wyszukiwania poprzez wciśnięcie klawisza ukośnika(/), wpisz w pole LOCALVERSION i zatwierdź poprzez wciśnięcie Entera. Powinieneś zobaczyć dwa wyniki:
Wyniki wyszukiwania w menuconfigu
Każdy wynik wyszukiwania ma przypisany numer, który jest widoczny u dołu każdego znaleziska. Nas interesuje pierwszy wynik, wciśnij więc klawisz 1 na swojej klawiaturze. Zostaniesz przeniesiony do kolejnego widoku:
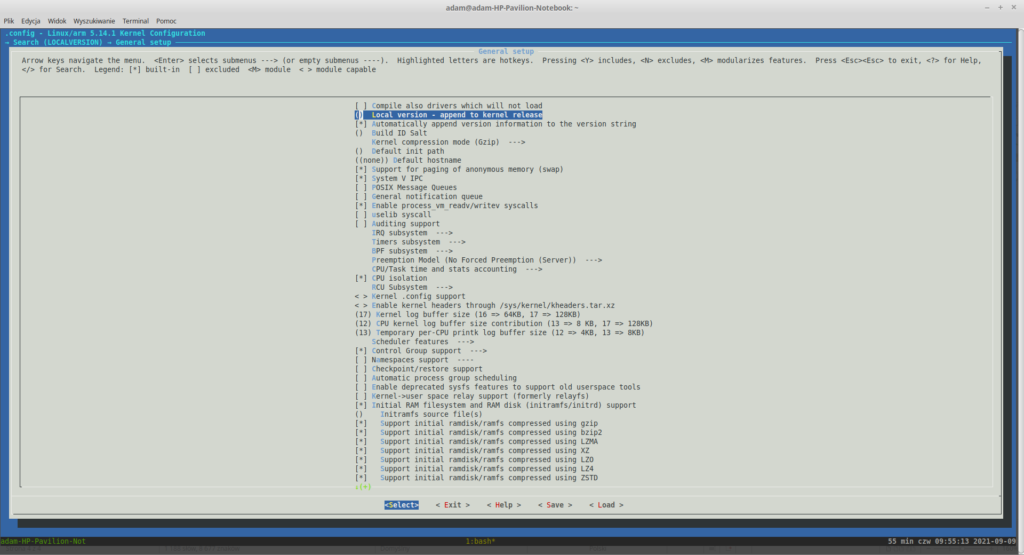
Edycja opcji LOCALVERSION
Wybierz tę opcje poprzez wciśnięcie Entera i w polu tekstowym wpisz coś w stylu:
-twojeimie-v1.0
Zatwierdź wartość poprzez ponowne wciśnięcie Entera.
Teraz musimy jakoś wyjść z tego całego menuconfiga. Na samym dole widać opcje Select, Exit, Help, Save oraz Load, nas interesuje Exit. Użyj strzałki w prawo aby przesunąć się na tę opcję i wyciśnij Enter, powtarzaj tę operacje dopóki nie wyjdziesz zupełnie z menuconfiga. Na samym końcu zostaniesz zapytany czy chcesz zapisać zmiany w konfiguracji. Wybierz oczywiście opcję Yes.
Mamy już skonfigurowany kernel teraz możemy przejść do jego budowania. Aby zbudować swój kernel użyj ponownie komendy make:
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- -j4
Dla przypomnienia, opcja -j informuje ile procesów do kompilacji może użyć make. Kompilacja powinna potrwać ok. 10 minut. Po kompilacji powstani trochę plików, nas interesują jedynie dwa:
Przełóż kartę do BBB, podłącz go do komputera za pomocą konwertera UART-USB uruchom go i przerwij automatyczny proces bootowania poprzez wciśnięcie dowolnego klawisza. Teraz możemy sprawdzić czy U-Boot widzi pliki, które przenieśliśmy na kartę uSD, użyj polecenia ext4ls:
ext4ls mmc 0:2
Pierwszy parametr to używany interfejs(karty uSD używają mmc), a kolejny to odpowiednio numer urządzenia i numer partycji. Po wykonaniu tego polecenia powinieneś zobaczyć coś podobnego do:
Pliki zostaną załadowane do adresów wskazywanych przez te zmienne, adresy gdzie należy ładować odpowiednie pliki są podawane przez producenta. Teraz możemy wystartować nasz system, aby tego dokonać musimy wykonać dwie czynności:
Ustalić parametry dla kernela
Wystartować system
Parametry kernela to podstawowe parametry systemu, które informują go którego portu szeregowego ma użyć do komunikacji albo gdzie ma szukać systemu plików. W U-Bootcie do przekazywania tych parametrów służy zmienna środowiskowa bootargs. Aby ją ustawić wykonaj następującą komendę:
Zwróć uwagę na brak znaku = w komendzie. Przekazujemy tutaj informacje o używanej przez system konsoli, prędkości transmisji danych(baudrate),każemy kernelowi wypisywać informacje z procesu bootowania(earlyprintk), wskazujemy mu również gdzie ma szukać rootfs, który jest do zapisu i odczytu(rw) oraz każemy Linuksowi czekać do momentu aż odpowiednie urządzenie z systemem plików zostanie wykryte przez system.
Teraz możemy wystartować Linuksa:
bootz ${kernel_addr_r} - ${fdt_addr_r}
bootz jest komendą, która startuje obrazy Linuksa w postaci zImage’a. Przyjmuje ona trzy parametry: adres kernela, adres initramfs oraz adres device-tree. W tym przypadku nie używamy initramfs więc podaliśmy myślnik(-) zamiast jakiegoś adresu.
Pewnie zauważyłeś już, że system nie wystartował tylko wyrzucił taki błąd:
[ 3.210883] EXT4-fs (mmcblk0p3): mounted filesystem with ordered data mode. Opts: (null). Quota mode: disabled.
[ 3.221231] VFS: Mounted root (ext4 filesystem) on device 179:3.
[ 3.227605] mmcblk1: p1 p2
[ 3.235743] devtmpfs: error mounting -2
[ 3.242666] Freeing unused kernel image (initmem) memory: 2048K
[ 3.249383] Run /sbin/init as init process
[ 3.253785] Run /etc/init as init process
[ 3.257958] Run /bin/init as init process
[ 3.262242] Run /bin/sh as init process
[ 3.266204] Kernel panic - not syncing: No working init found. Try passing init= option to kernel. See Linux Documentation/admin-guide/init.rst for guidance.
[ 3.280442] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 5.14.1-adam-v1.0 #3
[ 3.287266] Hardware name: Generic AM33XX (Flattened Device Tree)
[ 3.293399] [<c03116b0>] (unwind_backtrace) from [<c030be3c>] (show_stack+0x10/0x14)
[ 3.301212] [<c030be3c>] (show_stack) from [<c0fde258>] (dump_stack_lvl+0x40/0x4c)
[ 3.308834] [<c0fde258>] (dump_stack_lvl) from [<c0fdca58>] (panic+0x108/0x320)
[ 3.316184] [<c0fdca58>] (panic) from [<c0fe4908>] (kernel_init+0x110/0x124)
[ 3.323277] [<c0fe4908>] (kernel_init) from [<c03001b0>] (ret_from_fork+0x14/0x24)
[ 3.330888] Exception stack(0xc20bffb0 to 0xc20bfff8)
[ 3.335965] ffa0: 00000000 00000000 00000000 00000000
[ 3.344182] ffc0: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
[ 3.352398] ffe0: 00000000 00000000 00000000 00000000 00000013 00000000
[ 3.359059] ---[ end Kernel panic - not syncing: No working init found. Try passing init= option to kernel. See Linux Documentation/admin-guide/init.rst for guidance. ]---
Wynika to z faktu, że podaliśmy mu miejsce gdzie ma szukać rootfs i odpowiednie urządzenie jest znajdowane tylko, że nic tam nie ma, a przede wszystkim nie ma tam programu init, którego brak jest bezpośrednią przyczyną błędu.
W tym logu możesz również zobaczyć, że uruchomiony został twój kernel:
Pewnie też sobie pomyślałeś, że nie chce Ci się z każdym razem wpisywać tych wszystkich komend aby uruchomić Linuksa w U-Bootcie. Jest na to rozwiązanie- można ustawić zmienną bootcmd, która będzie uruchamiana podczas startowania U-Boota. Zresetuj BBB, przejdź do konsoli U-Boota i wydaj trzy polecenia:
Komenda saveenv powoduje, że zmienne środowiskowe zostaną zapisane na karcie uSD i będą dostępne przy ponownym uruchomieniu płytki. Możesz teraz ponownie zresetować BBB i zobaczyć, że system zacznie startować teraz automatycznie.
Raspberry Pi 4
RPi4 ze względu na swoją architekturę sprzętową nie używa standardowego kernela, używa za to jego spatchowanej wersji. Źródła można pobrać z githuba:
git clone --depth=1 --branch rpi-5.10.y https://github.com/raspberrypi/linux
cd linux
Ja tutaj używałem brancha rpi-5.10.y, ale Ty możesz użyć innego jeśli chcesz. Teraz musimy ustawić domyślną konfigurację:
make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- KERNEL=kernel8 bcm2711_defconfig
Zwróć uwagę na dodatkowy parametr KERNEL=kernel8, jest to charakterystyczne dla całej serii RPi.
Podobnie jak w przypadku BBB nie potrzebujemy nic modyfikować aby uruchomić kernel, ale jeśli chcesz możesz zmodyfikować opcję LOCALVERSION tak jak to było zaprezentowane dla BBB. Teraz możemy zbudować kernel:
make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- KERNEL=kernel8 -j4
Kompilacja powinna trwać ok. 20 minut. Po kompilacji powstanie troche nowych plików, ale tak jak w przypadku BBB nas interesują tylko dwa:
Teraz musisz zmodyfikować plik config.txt, który tworzyliśmy w poprzedniej lekcji i dodać w nim następującą linijkę:
kernel=Image
Informuje ona bootloader RPi4 o tym, który plik ma zostać użyty jako kernel. Podobnie jak w przypadku BBB musimy jakoś przekazać parametry kernela. Aby to zrobić utwórz na karcie uSD plik cmdline.txt o następującej zawartości:
Wszystkie opcje są opisane w sekcji poświęconej BBB.
Teraz możesz umieścić kartę uSD w RPi4, podłączyć ją do komputera za pomocą konwertera UART-USB i uruchomić ją. Podobnie jak w przypadku BBB powinieneś zobaczyć informację o braku pliku init, który to powinien znajdować się w rootfs, a którego nie ma bo nie ma rootfs.
QEMU
Dla QEMU zbudujemy kernel dla trzech różnych architektur: ARM, ARM64 oraz x86_64. Pobierz paczkę z kodem i ją rozpakuj:
wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.14.1.tar.xz
tar xf linux-5.14.1
Możesz utworzyć trzy wersje tego katalogu- dla każdej architektury:
Uwagi dla wszystkich architektur- nie będziemy potrzebowali w żaden sposób modyfikować tych kerneli jednak jeśli chcesz mieć pewność, że uruchamia się twój kernel możesz zmodyfikować opcję LOCALVERSION tak jak to jest w przypadku BBB, ale najpierw musimy ustalić domyślne konfiguracje.
Odnośnie QEMU, w przypadku architektury ARM będziemy używać modelu versatilepb, w przypadku ARM64 użyjemy generycznego modelu virt, a dla x86_64 użyjemy modelu pc.
A teraz do rzeczy, musimy zdefiniować domyślne konfiguracje dla każdej z architektur:
# dla ARM:
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- versatile_defconfig
# dla ARM64:
make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- defconfig
# dla x86_64
make ARCH=x86 x86_64_defconfig
Zwróć uwagę, że w przypadku architektury x86_64 nie używamy opcji CROSS_COMPILE, wynika to z faktu, że budujemy kod na tę samą architekturę co maszyna budująca zatem nie dokonujemy tutaj cross-kompilacji.
Kompilacje kerneli będą się wahać od ok. 5 minut dla ARMa do ok. 15-20 minut dla ARM64 i x86_64.
W wyniku kompilacji powstanie troche plików nas interesują tylko następujące pliki:
Omówienie powyższych komend zacznijmy od omówienia parametrów QEMU:
-m: ilość pamięci RAM przydzielonej do emulatora
-M: używany model
-cpu: używany model procesora, nie jest konieczne gdy używamy konkretnego modelu
-smp: ilość emulowanych rdzeni procesora, nie jest konieczne gdy używamy konkretnego modelu
-kernel: obraz kernela, który ma zostać użyty
-dtb: plik device-tree
-append: parametry przekazywane do kernela
-nographic: wyłączenie trybu graficznego, wszystkie dane będą przekazywane na port szeregowy
W przeciwieństwie do BBB oraz RPi4 w parametrach przekazywanych do kernela nie podawaliśmy miejsca gdzie jest rootfs, wynika to z faktu, że nie podłączaliśmy żadnego obrazu dysku do QEMU(to zostanie zaprezentowane przy okazji budowania rootfs w kolejnej lekcji). Z tego też powodu błąd który się pojawia podczas startowania Linuksa wygląda tutaj nieco inaczej niż w przypadku BBB oraz RPi4 i wygląda on tak:
[ 2.854777] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
[ 2.855450] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 5.14.1-adam-v1.0 #1
[ 2.855877] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.14.0-0-g155821a1990b-prebuilt.qemu.org 04/01/2014
[ 2.856483] Call Trace:
[ 2.857531] dump_stack_lvl+0x33/0x42
[ 2.857767] panic+0xf3/0x2b4
[ 2.857900] mount_block_root+0x17d/0x21d
[ 2.858099] ? __SCT__tp_func_drv_return_u64+0x8/0x8
[ 2.858278] ? rdinit_setup+0x26/0x26
[ 2.858394] mount_root+0xec/0x10a
[ 2.858514] prepare_namespace+0x130/0x15f
[ 2.858725] kernel_init_freeable+0x217/0x226
[ 2.858914] ? rest_init+0xc0/0xc0
[ 2.859075] kernel_init+0x11/0x110
[ 2.859240] ret_from_fork+0x22/0x30
[ 2.860387] Kernel Offset: 0x13200000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)
[ 2.861172] ---[ end Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) ]---
Tutaj mamy informację o nie możliwości zamontowania rootfsa ponieważ nie został on wskazany. Możesz mieć jednak pewność, że startowałeś swój własnoręcznie zbudowany kernel, powinieneś widzidzieć log podobny do:
Teraz jest jeszcze ostatnia zagadka- jak wyłączyć to całe QEMU? Podpowiem, że znana kombinacja klawiszy Ctrl+C nie zadziała. Aby wyłączyć QEMU musimy przejść do jego monitora poprzez wciśnięcie kombinacji Ctrl+A, a następnie wciśnięciu klawisza C. Wtedy pojawi się znak zachęty wyglądający następująco:
(qemu)
Teraz wpisz komendę ”q”(tak, dosłownie jedna litera) i wciśnij Enter.
W tej lekcji budowaliśmy kernel dla trzech architektur w QEMU, w przyszłych lekcjach ograniczymy się do prezentowania przykładów tylko dla modelu versatilepb, a dla pozostałych będę podawać tylko konfiguracje, które są potrzebne do przebudowania odpowiedniego oprogramowania.
W kolejnej lekcji uruchomimy już nasz system, będziemy budować rootfs, przez którego to brak nie mogliśmy wystartować naszego systemu.